[REAL Python – Flask] – “SQLAlchemy 에서 Session.commit() 후 저장된 모델 객체 얻어오기”
[REAL Python – Flask] – “SQLAlchemy 에서 Session.commit() 후 저장된 모델 객체 얻어오기”
생겼던 문제 사항
Sqlalchemy 사용 시 모델 객체를 만들고, 모델 객체를 데이터베이스에 실제로 저장하고 저장된 모델 객체를 받아오지 못하는 문제가 있었습니다.
이게 무슨 말인고 하니..
현재 애플리케이션에서 레이어별로 요청이 처리되는 과정
이전 시간에 고민하고 고민했던 그 구조를 그림으로 잠깐 살펴보겠습니다.
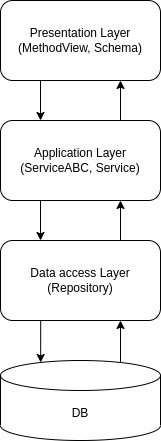
위와 같은 레이어드 아키텍처에서는 각각의 레이어가 다른 레이어가 어떻게 임무를 수행하는지 몰라야 합니다. 단지 맡은 역할을 충실히 수행할 뿐이죠. 예컨대 Application Layer 는 Data Access Layer 가 데이터를 어디서 가져오는지 몰라야 합니다. 같은 말로 Data Access Layer 는 불필요한 정보를 노출하면 안 됩니다.
분명, “몰라야 합니다” 라는 말에 거부감이 느껴지셨을 겁니다. 그래 봤자 각각의 레이어들은 .py 로 끝나는 파이썬 파일들인데, 파이썬 인터프리터에 의해 해석되고 실행되는 텍스트로 이루어진 것들 뿐인데 말입니다.
아래의 예시를 살펴보겠습니다. 치킨집에서 주문이 이루어지는 과정을 간단하게 나타내 봅시다.

- “손님” 은 전화를 받는 카운터 직원이 어디 사는 누구인지를 모릅니다. 그리고 알 필요도 없습니다. 남몰래 짝사랑하고 있던 것이 아닌 이상 말입니다. 단지 손님의 역할은 “내가 먹고 싶은 치킨의 종류를 알려주고, 주문을 완료하는 것” 이고 그것에만 관심이 있죠. 전화를 받는 사람의 성별, 나이, 이름 모두 관심이 없습니다.
- “카운터 직원” 은 손님의 전화를 받고 “후라이드 치킨 한 마리” 라는 주문을 얻었습니다. 마찬가지로 “카운터 직원” 은 후라이드 치킨을 만드는 사람의 나이, 이름, 성별, 취향 그 어느 것에도 관심이 없습니다. 단지 카운터 직원의 역할은 “손님으로부터 받은 주문을, 주방 직원에게 잘 전달해주는 것” 이죠.
- 마찬가지로 주방 직원 또한 “치킨을 만드는 것” 에만 관심이 있습니다. 손님이 개를 먹이기 위해 치킨을 시켰건, 베게로 베고 잠자기 위해 치킨을 시켰건 자신의 역할인 “치킨을 만드는 것” 만 수행할 뿐이죠.
좋아요. 위의 예시로 “관심이 없다” 라는 말에 대한 튜닝을 진행했으니, 아래의 코드를 살펴봅시다.
@auth_api.route("/users/")
class UserListAPI(MethodView):
"""사용자 목록을 다루는 API 입니다."""
@inject
def __init__(self, user_service=Provide[UserContainer.user_service]):
self.user_service = user_service
@auth_api.arguments(PaginateArgsSchema, location="query") # 페이지네이션 파라미터
@auth_api.arguments(SortingArgsSchema, location="query") # 정렬 파라미터
@auth_api.arguments(UserFilteringArgsSchema, location="query") # 필터링 파라미터
@auth_api.response(200, UserListSchema)
def get(
self,
paginate_args,
sorting_args,
user_filtering_args,
):
return self.user_service.get_list(
paginate_args, sorting_args, user_filtering_args
)위는 실제 프로젝트의 presentation layer 코드의 일부입니다 : 딴 것은 보지 않더라도, 위의 @auth_api.route("/users/") 에서 라우팅을, return self.user_service.get_list(paginate_args, sorting_args, user_filtering_args) 에서 Service Layer 를 호출한다는 것을 직관적으로 캐치해내실 수 있을 것입니다.
“손님” 은 전화를 받는 카운터 직원이 어디 사는 누구인지를 모릅니다. 그리고 알 필요도 없습니다. 남몰래 짝사랑하고 있던 것이 아닌 이상 말입니다. 단지 손님의 역할은 “내가 먹고 싶은 치킨의 종류를 알려주고, 주문을 완료하는 것” 이고 그것에만 관심이 있죠. 전화를 받는 사람의 성별, 나이, 이름 모두 관심이 없습니다.
코드에 대한 설명과, “손님” 에 대한 설명을 읽어본다면 확실히 매치가 됩니다: Presentation Layer 는 클라이언트로부터 적절한 데이터가 들어왔는지, 잘못된 건 없는지를 검증하고 아래의 Application Layer 에게 역할을 위임할 뿐 다른 것은 알고 있지도 않고, 관심도 없습니다.
그렇다면, 아래의 코드도 바로 직관적인 이해가 가능할 것입니다:
def get_list(
self,
pagination_request_params: dict,
ordering_params: dict,
user_filtering_params: dict,
) -> PaginationResponseEntity[UserEntity]:
# pagination 기본값 정하기
page = pagination_request_params.get("page", 1)
per_page = pagination_request_params.get("per_page", 10)
# Data Access Layer 호출
return self.user_repository.read_all(
page=page, per_page=per_page, filter_by=filter_by, ordering=ordering
)위는 UserService 클래스의 get_list 메서드입니다. pagination 정책에 따라서 기본값을 정해주고, 그렇게 정제된 데이터들과 함께 data access layer 에게 “사용자 목록 데이터 좀 이렇게 뽑아줘!” 를 요청하고 있죠. 페이지네이션 정책을 정하고, 어떤 비즈니스 로직을 수행하는 것은 이 get_list 의 책임이지만, 데이터를 가져오는 건 Data Access Layer 의 역할이라는 겁니다.
Data Access Layer 는 획일화된 데이터를 반환해 주어야 한다.
이 주제를 소제목으로 둔 것은 여기부터 문제가 생겼기 때문입니다.
현재 저는 데이터베이스에서 데이터를 쿼리하는 등 데이터를 가져오거나 다루는 것을 Python ORM 중 하나인 SQLAlchemy 를 통하여 수행하고 있습니다.
그리고, 실제로 Python ORM 에는 SQLAlchemy 말고도 상당히 많은 ORM 구현들이 존재합니다.

SQLAlchemy,

Peewee,
TortoiseORM,

Django ORM 등 상당히 많은 ORM 구현들이 존재하죠.
그러면, 여기서 조금 문제가 생깁니다.
위와 같은 레이어드 아키텍처에서는 각각의 레이어가 다른 레이어가 어떻게 임무를 수행하는지 몰라야 합니다. 단지 맡은 역할을 충실히 수행할 뿐이죠. 예컨대
Application Layer는Data Access Layer가 데이터를 어디서 가져오는지 몰라야 합니다. 같은 말로Data Access Layer는 불필요한 정보를 노출하면 안 됩니다.
라고 소개했습니다. 사실 Application Layer 는 Data Access Layer 에서 이놈이 데이터를 in-memory 에서 가져오든, ORM 구현을 통해서 가져오든, 심지어 SQL 을 직접 수행하여 가져오든 관심이 없습니다. 원하는 건 “데이터” 일 뿐이었죠. 아침에 카페에 나가 커피를 시켰을 때, 커피숍 안에서 부산 사는 민수가 커피를 만들던, 강남 사는 상태가 만들던 손님은 “커피” 라는 결과만 원하듯이 말입니다.
하지만, SQLAlchemy model 이 반환해주는 데이터는 꽤 SQLAlchemy 종속적인 데이터입니다.
In [5]: UserModel.query.first().__dict__
Out[5]:
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState at 0x7f62346c2ed0>,
'id': 1,
'email': 'goddessana@naver.com',
'username': 'goddessana',
'updated_at': datetime.datetime(2023, 4, 30, 11, 12, 53),
'role': <Roles.ADMIN: 0>,
'study_id': None,
'created_at': datetime.datetime(2023, 4, 30, 11, 12, 53),
'uuid': '04b3c37c-951a-47eb-8700-60548066b815'}
위의 코드에서 _sa_instance_state 는 SQLAlchemy ORM 에서만 내부적으로 존재하는 값입니다. 이 데이터를 바로 Application Layer 로 넘겨준다면, 그건 Application Layer 가 Data Access Layer 가 어떤 방식으로 데이터를 가져온다는 것을 알게 된다는 것을 의미합니다. 또, '_sa_instance_state' 와 같은 값을 처리하기 위해서 별도의 코드가 필요하다면 Service Layer 와 Application Layer 사이에 강한 결합이 생겨 둘 중 어느 하나도 다른 것으로 갈아치우지 못하는 코드가 되어 버리죠.
그래서 생각한 것은 애초에 Data Access Layer 에서 “획일화된 데이터 구조” 를 반환하도록 하는 것이었습니다. 그리고 plain python object 로 그것을 구현하고자 한 것이죠. Python 에서는 Dataclass 를 통해서 아래와 같은 엔티티를 정의할 수 있습니다.
from dataclasses import dataclass
from datetime import datetime
from enum import Enum
from typing import Optional
@dataclass
class UserEntity:
id: Optional[int]
uuid: Optional[str]
email: str
role: Enum
username: str
created_at: datetime
updated_at: datetime
study_id: Optional[int] = None # foreign key
위는 실제로 구현된 UserEntity 클래스입니다. 코드 중 어디를 찾아봐도 Python 내부 기능들만 사용하고 있을 뿐, ORM 이나 웹 프레임워크와 관련된 코드들은 전혀 보이지 않는 것을 알 수 있죠.
def read_by_id(self, id) -> Optional[DBEntity]:
if id is None:
raise ValueError("id cannot be None.")
query_result = self.db.session.get(self.sqlalchemy_model, id)
if query_result:
return self._sqlalchemy_model_to_entity(query_result)
return None
그렇다면 위와 같이 데이터베이스에서 모델을 가져오고, 해당 모델을 엔티티로 바꿔 반환해 줌으로서 Service Layer 와 Data Access Layer 사이에서 데이터 형태의 일관성을 보장해줄 수 있습니다. Service Layer 는 Data Access Layer 가 데이터를 어디서, 어떻게 가져오는지에 대해 상관없이, UserEntity 객체를 얻기를 기대하게 됩니다.
그런데, 여기서 진짜 문제가 생깁니다.(또..)
SQLAlchemy 에서 저장 후, Entity 로 변환하기
def read_all(
self, pagination_entity, filtering_entity, sorting_entity
) -> List[Optional[DBEntity]]:
return [
self._sqlalchemy_model_to_entity(query_result)
for query_result in self.db.session.execute(select(self.sqlalchemy_model))
pk.name for pk in inspect(self.sqlalchemy_model).primary_key
]
if len(sqlalchemy_model_pk_names) == 1:
dump_data = self._get_schema().dump(sqlalchemy_instance)
return self.entity(**dump_data)처음에 생각했던 것은 Repository 에서 위와 같이 데이터를 읽어온 다음, 그 모든 데이터들을 Entity 로 변환해 주는 것이었습니다: Flask-Marshmallow 의 SQLALchemyAutoSchema 를 이용해 모델에 대한 덤핑 데이터를 얻어서, 그것을 엔티티에 직접 넣어주는 것이었죠. 위 아이디어는 괜찮았지만, 직렬화되는 데이터가 무조건 문자열로만 진행된다는 것이 문제였습니다.
# presentation layer
class UserSchema(Schema):
"""사용자 한 명에 대한 직렬화 규칙을 정의합니다."""
uuid = fields.UUID(
dump_only=True,
metadata={"description": "사용자 UUID"},
)
username = fields.String(
metadata={"description": "사용자 닉네임"},
)
email = fields.Email(
metadata={"description": "사용자 이메일"},
)
created_at = fields.DateTime(
dump_only=True,
metadata={"description": "사용자 가입일자"},
)
updated_at = fields.DateTime(
dump_only=True,
metadata={"description": "사용자 정보 수정일자"},
)
그렇기 때문에, “데이터를 어떻게 보여줄 것인가” 를 결정해주는 presentation layer 의 schema 에서 위와 같이 DateTime 필드를 쓸 수가 없었죠.
실제로 Marshmallow 에서는 DateTime 에 대한 정보를 어떻게 보여줄 것인지를 결정할 수 있습니다. rfc, iso8601, unix timestamp 와 같이 말이죠.
하지만, Repository 에서 반환해주는 UserEntity 객체의 각각의 속성은 모두 str 이므로 Marshmallow Schema 는 필드에 대한 적절한 처리를 하지 못하게 됩니다. 이게 문제였던 거죠.
__dict__ 를 통해서, UserModel 에서 바로 속성 가져오기
In [2]: UserModel.query.first().__dict__
Out[2]:
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState at 0x7fbdaac8bdd0>,
'email': 'goddessana@naver.com',
'id': 1,
'username': 'goddessana',
'updated_at': datetime.datetime(2023, 4, 30, 11, 12, 53),
'study_id': None,
'role': <Roles.ADMIN: 0>,
'created_at': datetime.datetime(2023, 4, 30, 11, 12, 53),
'uuid': '04b3c37c-951a-47eb-8700-60548066b815'}
위에서, 저는 잠깐 __dict__ 속성을 통해서 한 모델 객체가 가지고 있는 데이터를 가져오는 예시를 보여드린 적이 있습니다. 위와 같았죠.
그렇기에, 생각했던 건 위의 부분에서 SQLAlchemy 에 종속적인 속성인 '_sa_instance_state' 만 빼고, UserEntity 객체로 인스턴스를 만들면 되겠다는 생각이었습니다.
def _sqlalchemy_model_to_entity(self, sqlalchemy_instance) -> DBEntity:
# 생략..
instance_dict = sqlalchemy_instance.__dict__
instance_dict.pop("_sa_instance_state")
return self.entity(**instance_dict)그렇기에, 처음 시도했던 위의 코드를 보면 바로 __dict__ 를 얻어온 다음, “sa_instance_state” 를 pop 한 다음 UserEntity 에 넣어주는 것을 볼 수 있죠. 그리고 실제로 이것은 잘 작동했습니다. 읽기 작업에서만 말이에요.
SQLAlchemy 에서 데이터 저장 후 모델 객체를 얻을 수가 없다..?
def save(self, entity: DBEntity) -> DBEntity:
model_instance = self._entity_to_sqlalchemy_model(entity)
with self.db.session.begin():
self.db.session.add(model_instance)
print(model_instance)
print(model_instance.__dict__)
return self._sqlalchemy_model_to_entity(model_instance)위의 print 문의 결과가 어떨 것이라고 생각하시나요? 저는 SQLAlchemy 에서 commit() 을 끝낸 후, 모델 객체에 대한 업데이트까지 SQLAlchemy 가 수행해 줄 것이라고 생각했습니다.
<UserModel 1>
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7fbd4000d8b0>}?!
분명히 이미 존재하는 데이터에 대해서는 모든 속성들이 __dict_ 를 통해서 잘 찍히던 것이, 위의 코드에서는 딱 필요한 부분들만 빼고 나와버린 겁니다.
원인과 해결책 : SQLAlchemy 의 Lazy Loading, db.session.refresh() 호출
이는, 실제 __dict__ 속성에 접근할 때에 데이터베이스에 있는 값을 로드하지 않고, 메모리에 존재하는 값만 로드하기 때문인 것으로 보입니다. 그리고 expired 된 model 객체에 대한 값을 얻으려고 했기 때문이기도 합니다.
{'modified': False, '_orphaned_outside_of_session': False, 'insert_order': 1, 'session_id': 1, '_strong_obj': None, 'mapper': <Mapper at 0x7fa48a149450; UserModel>, 'key': (<class 'core.repositories.test_sqlalchemy_repository.UserModel'>, (1,), None), '_instance_dict': <weakref at 0x7fa486a9ebb0; to 'WeakInstanceDict' at 0x7fa486ab47d0>, 'expired': True}
위의 “expired” 의 값이 True 인 것이 보이시나요? 실제 SQLAlchemy 공식 문서에서도 아래와 같이 예시를 제공해 주고 있네요.
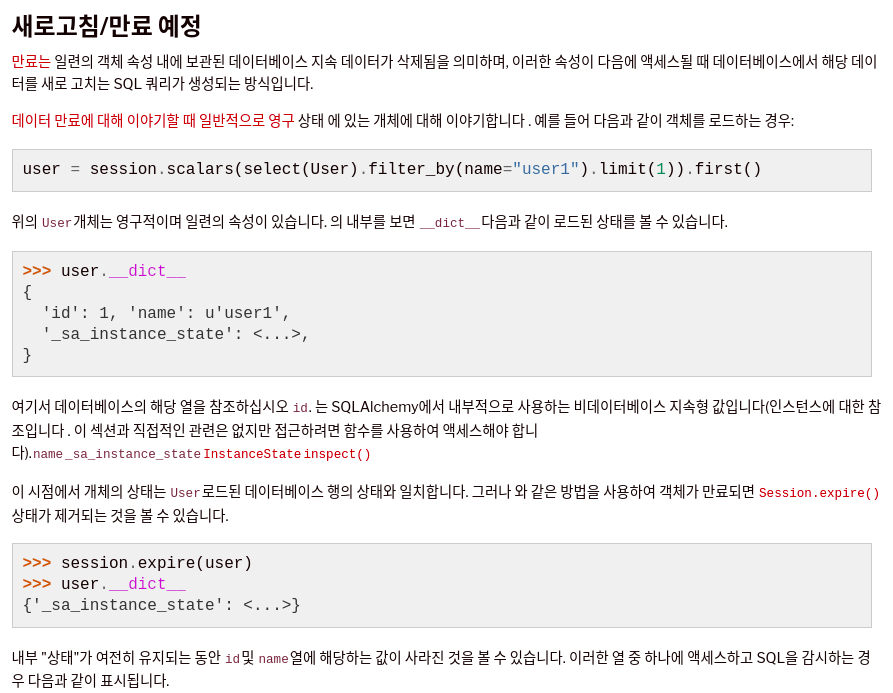
https://docs.sqlalchemy.org/en/20/orm/session_state_management.html
에서 상세 문서 내용을 확인할 수 있습니다.
사실, 위의 시도했던 코드 중 일부에서 model_instance.username 과 같이 해당 모델의 속성에 접근하려고 시도하면 코드가 문제없이 작동하는 것을 확인할 수 있었습니다. 그리고 그것은 SQLAlchemy 의 Lazy Loading 때문이었고요.
def save(self, entity: DBEntity) -> DBEntity:
model_instance = self._entity_to_sqlalchemy_model(entity)
with self.db.session.begin():
self.db.session.add(model_instance)
print(model_instance.name)
print(model_instance.__dict__)
return self._sqlalchemy_model_to_entity(model_instance)
# {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7f971297b7d0>, 'name': 'mr_fullask', 'id': 1}

위의 print(dmoel_instance.__dict__) 가 호출될 때에 실제로 SELECT 문이 날아가고, 모델 인스턴스가 업데이트 됨으로서 __dict__ 가 실제 데이터베이스의 값들을 가지고 있는 상태가 될 수 있던 것이었죠.
결국, 아래처럼 db.session.refresh(model_instance) 코드를 추가하여 해결하였습니다.
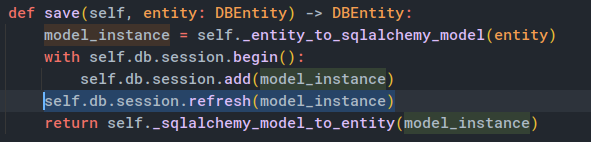
평소에는 빠르게 작성하기 위해서 이런 ORM 이 어떻게 동작하는지(이 주제도 물론 어떻게 동작하는지의 깊은 부분을 다룬 것은 아니지만), 그리고 왜 그렇게 동작하는지 공식 문서를 찾아보며 읽어보지는 않았는데, 개인적으로 ORM 을 통해서 이런 Repository Pattern 을 구현하다 보니 ORM 에 대한 이해도가 상당히 높아야겠구나 하는 생각이 듭니다.
이번 문제를 겪으며, 테스트 코드에 대한 중요성도 깨닫게 되었는데 – Repository 에 대한 각각의 메서드의 테스트 코드를 작성해 놓았기 때문에 문제를 발견할 수 있었기 때문입니다.
하지만, 커밋 시 확인하고 커밋을 했어야 하는데 어느 순간부터 그냥 하다 보니 문제를 뒤늦게 발견한 것도 문제이긴 했네요..
이 문제를 해결하기 위해서, 나중에는 pre-commit 같은 기능도 어서 도입해 봐야겠습니다.