[Flask] – “어떻게 Flask 프로젝트를 구성할 것인가?”
[Flask] – “어떻게 Flask 프로젝트를 구성할 것인가?”
Down The Rabbit Hole!

“Flask 로 프로젝트 레이아웃을 어떻게 짤 것인가?” 는 제가 Flask 를 사용하기 시작할 때부터 큰 궁굼증이었습니다. Django app 처럼 프레임워크 단에서 기본적인 레이아웃을 제공해주는 것이 있는 것도 아니고, 대부분의 예제들은 하나의 app.py 혹은 Blueprint 를 어느 정도 사용한 것들이었기 때문입니다.
이번에 새로운 프로젝트를 시작하게 되면서, 어떤 고민을 했는지 – 그런 고민들이 이전 프로젝트에서는 어떻게 녹아들어가 있었는지를 알아보며, 저만의 Best Practice 를 구성해 보는 과정을 기록해보고자 합니다.
참고 : 이것은 저의 개인적인 고민과 삽질, 그리고 그것을 해결하는 과정을 적은 기록일 뿐입니다. 특정 용어나 개념에 대한 제대로 된 설명이나 정의는, 다른 신뢰할만한 곳에서 찾는 것을 추천드립니다!
그럼 진짜로 토끼굴로 내려가 봅니다. LETS DANCE!
Flastagram
기존 인스타그램 클론코딩 튜토리얼에서는, 대략적으로 아래와 같은 구조로 프로젝트가 구성되었습니다.
https://github.com/TGoddessana/flastagram
./backend
├── Dockerfile
├── api
│ ├── __init__.py
│ ├── db.py
│ ├── ma.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── comment.py
│ │ ├── post.py
│ │ └── user.py
│ ├── resources
│ │ ├── __init__.py
│ │ ├── comment.py
│ │ ├── image.py
│ │ ├── post.py
│ │ └── user.py
│ ├── schemas
│ │ ├── __init__.py
│ │ ├── comment.py
│ │ ├── image.py
│ │ ├── post.py
│ │ └── user.py
│ └── utils
│ ├── __init__.py
│ └── image_upload.py
├── app.py
├── requirements
│ ├── common.txt
│ ├── dev.txt
│ └── prod.txt
├── requirements.txt
위의 구조는 각각 아래의 역할을 가집니다.
- models – ORM 코드가 위치한 부분, 하나의 클래스는 하나의 테이블로 매핑됨
- resources – 실제 HTTP 클라이언트의 요청을 받아들이는 부분
- schemas – ORM object <-> JSON 의 변환을 담당하는 부분
위의 구조에서 찾을 수 있는 문제점은 아래와 같았습니다:
resource, 너의 책임은 뭐야?
post_schema = PostSchema()
post_list_schema = PostSchema(many=True)
class Post(Resource):
@classmethod
@jwt_required()
def get(cls, id):
post = PostModel.find_by_id(id)
if post:
user = UserModel.find_by_username(get_jwt_identity())
_post_schema = PostSchema(context={"user": user})
return _post_schema.dump(post), 200
else:
return {"Error": "게시물을 찾을 수 없습니다."}, 404
@classmethod
@jwt_required()
def put(cls, id):
"""
게시물의 전체 내용을 받아서 게시물을 수정
없는 리소스를 수정하려고 한다면 HTTP 404 상태 코드와 에러 메시지를,
그렇지 않은 경우라면 수정을 진행
"""
post_json = request.get_json()
# first-fail 을 위한 입력 데이터 검증
validate_result = post_schema.validate(post_json)
if validate_result:
return validate_result, 400
username = get_jwt_identity()
author_id = UserModel.find_by_username(username).id
post = PostModel.find_by_id(id)
# 게시물의 존재 여부를 먼저 체크한다.
if not post:
return {"Error": "게시물을 찾을 수 없습니다."}, 404
# 게시물의 저자와, 요청을 보낸 사용자가 같다면 수정을 진행할 수 있다.
if post.author_id == author_id:
post.update_to_db(post_json)
else:
return {"Error": "게시물은 작성자만 수정할 수 있습니다."}, 403
return post_schema.dump(post), 200
@classmethod
@jwt_required()
def delete(cls, id):
post = PostModel.find_by_id(id)
if post:
post.delete_from_db()
return {"message": "게시물이 성공적으로 삭제되었습니다."}, 200
return {"Error": "게시물을 찾을 수 없습니다."}, 404
위의 코드를 살펴보겠습니다. Flask-Restful 의 Resource 를 사용해서 api 가 작성된 것을 볼 수 있습니다. Django 의 Generic View 에서 영감을 받은 Flask 의 MethodView 를 상속받아 만들어진 것이 Flask-Restful 의 Resource 인데, 각각의 HTTP 소문자 메서드를 작성하면 프레임워크 단에서 그것을 적절하게 처리해 줍니다. 위의 경우, get, put, delete 메서드가 작성되어있네요.
위의 메서드들 중, 딱 보기에도 코드가 가장 많아 보이는 put 메서드를 더 살펴봅시다:
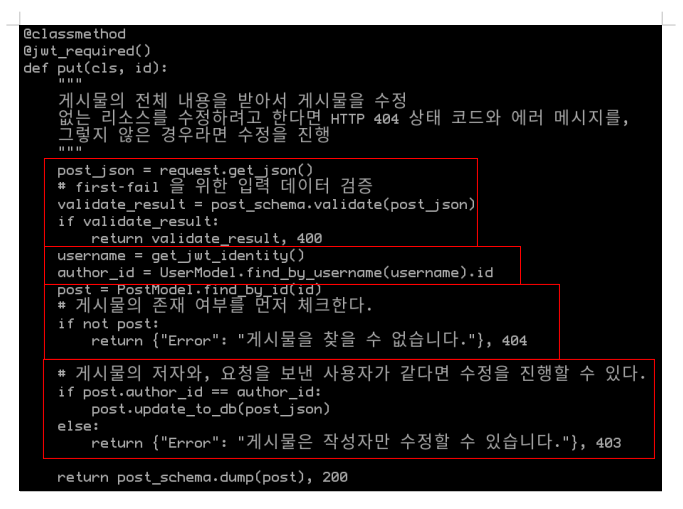
put 메서드는 다음과 같은 일을 합니다:
- 클라이언트로부터 들어온 데이터를 검증한다.
- 게시물이 존재하는지를 체크한다.
- 해당 엔드포인트를 이용할 수 있는지, 권한을 체크한다.
- 수정된 게시물을 데이터베이스에 저장한다.
- 수정된 게시물의 정보를 적절하게 직렬화하여 클라이언트에게 응답한다.
위의 로직들은 분명히 흔히 사용되고, 여러 곳에서 재사용될 수도 있는 로직들입니다. 단순히 게시물 수정과 같은 기능이기에 위의 코드가 그리 길어 보이지 않을 수 있지만 – 비즈니스 로직이 복잡해진다면 스파게티 코드가 될 가능성이 다분해 보이죠. 더불어 “내가 작성한 게시물은 나만 작성할 수 있다”는 대부분의 게시판 서비스에서 적용되는 흔한 요구사항입니다. 이를 위해서 중복되는 코드들을 함수로 관리하거나, 이 역할을 수행하는 클래스를 만드는 등의 작업을 하지 않고 – 그냥 로직을 구현해 버렸네요.
위와 같이 흔히 중복되는 로직들을 묶지 않으면 아래와 같은 문제가 발생하게 됩니다:
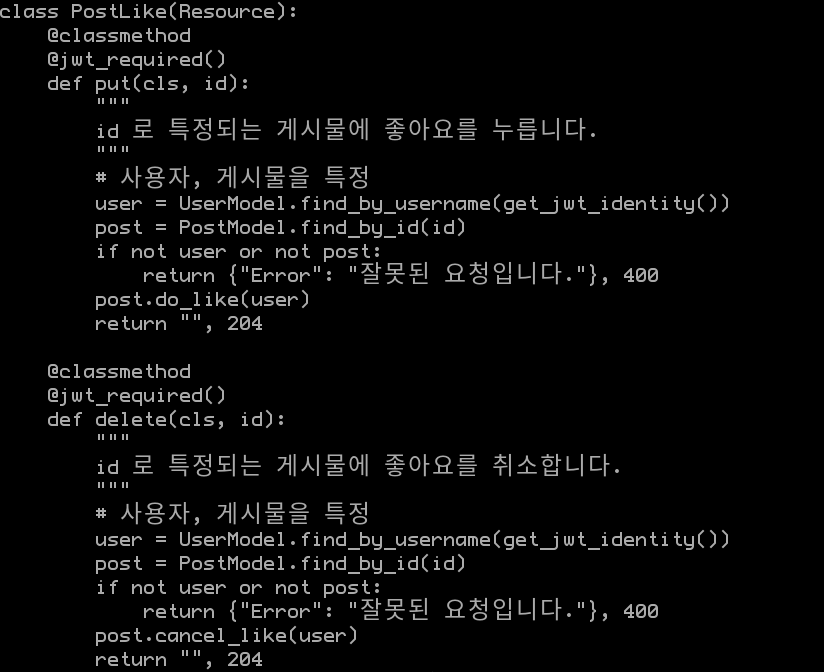
위는 “게시물 좋아요, 좋아요 취소” 를 처리하는 클래스입니다. 자세히 보면 같은 코드가 자그마치 몇 줄이나 반복이 됩니다. 이런 경우 문제가 되는 것은 – “게시물과 사용자를 특정하는 방법이, ID가 아니라 UUID로 바뀌었습니다!” 와 같은 변경사항이 생길 경우, 자그마치 위의 4줄을 모두 바꿔야 한다는 겁니다. 이것은 위의 메서드뿐만 아니라 “ID로 게시물과 사용자를 찾는 모든 코드” 들을 resources.py 에서 찾아 바꿔야 한다는 이야기이기도 하죠. 변경사항에 굉장히 취약합니다.
분명히, 코드에는 문제가 있습니다. 유지보수를 위해서 더 나은 방식을 고민해봐야 합니다.
난 너만 바라보겠어, model!
또 문제가 되는 부분은 resources 가 model 을 강력하게 의존하고 있다는 것입니다. 문제가 되는 예제를 볼까요?:
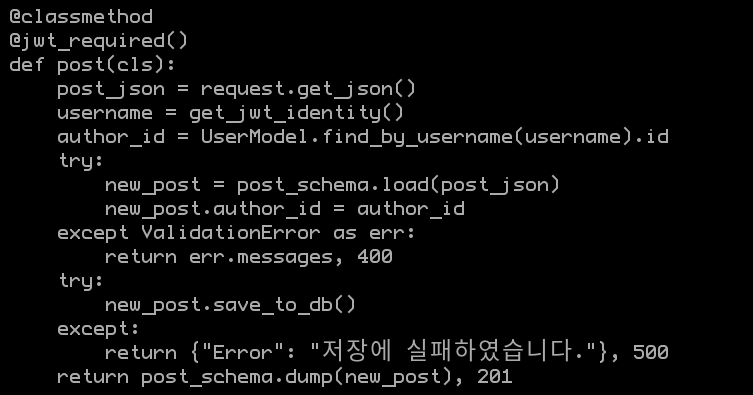
위의 코드는 /posts/ 로 http POST 요청이 날아오면 사용자의 json payload 를 새로운 게시물로 저장하는 역할을 합니다.
위의 코드에서 resource 는 UserModel 코드에 대해서 강력하게 의존하고 있습니다. 그 중 어느 것도 갈아끼우기 쉽지 않아 보입니다. 위의 코드를 살펴보다 보면, UserModel.find_by_username() 과 같은 메서드를 사용하는 것을 볼 수 있는데, 만약 이와 같은 ORM 구현에 변경이 생긴다면 분명 ORM 코드를 바꾼 것임에도 resources 코드도 수정해야 하는 문제가 생깁니다.
확실히, 관심사를 분리해야 합니다. resources 가, ORM 구현체의 종류에 상관없이 마음 편하게 게시물 데이터를 클라이언트에게 보여줄 수 있게끔요. 이 부분에도 문제가 있죠.
Django 의 Fat Model with thin View? 엄..
Django 에서, “비즈니스 로직을 어디에 둘 것인가?” 는 Django 커뮤니티에서 심심하면 타오르는 논쟁거리입니다.
Django 의 설계 철학 : Active Record Pattern
Django 는 Active Record 패턴을 간접적으로 따르고 있습니다. 이는 Django 공식 홈페이지의 “설계 철학” 부분에서도 볼 수 있죠. 모델에 도메인 로직을 작성하는 겁니다.
https://docs.djangoproject.com/en/4.2/misc/design-philosophies/#include-all-relevant-domain-logic

모든 도메인 로직을 모델에 작성함으로서, View 혹은 Serializer, Form 을 얇게 유지할 수 있습니다. 그리고 저는 이 방법에 굉장히 매료되어 있었죠.
Flask 의 SQLAlchemy 와 함께 적용해 봤던 Active Record Pattern
이 때의 저는 Flastagram 에서도 이를 간접적으로 차용했습니다. 아래와 같은 코드가 예시가 될 수 있겠죠.
class PostModel(db.Model):
"""
Flastagram 게시물 모델
title : 게시물의 제목, 150자 제한
content : 게시물의 내용, 500자 제한
created_at : 게시물의 생성일자, 기본적으로 현재가 저장
updated_at : 게시물의 생성일자, 게시물이 수정될 때마다 업데이트
author_id : 게시물의 저자 id, 외래 키
comment_set : 게시물에 달린 댓글들
image : 게시물에 첨부된 이미지 파일의 주소
"""
__tablename__ = "Post"
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(150))
content = db.Column(db.String(500))
created_at = db.Column(db.DateTime(timezone=True), default=func.now())
updated_at = db.Column(
db.DateTime(timezone=True), default=func.now(), onupdate=func.now()
)
author_id = db.Column(
db.Integer,
db.ForeignKey("User.id", ondelete="CASCADE"),
nullable=False,
)
author = db.relationship("UserModel", backref="post_set")
comment_set = db.relationship(
"CommentModel", backref="post", passive_deletes=True, lazy="dynamic"
)
image = db.Column(db.String(255))
liker = db.relationship(
"UserModel",
secondary=post_to_liker,
backref=db.backref("post_liker_set", lazy="dynamic"),
lazy="dynamic",
)
def do_like(self, user):
"""
특정 게시물에 좋아요를 누름
"""
if not self.is_like(user):
self.liker.append(user)
db.session.commit()
return self
def cancel_like(self, user):
"""
특정 게시물에 좋아요를 취소함
"""
if self.is_like(user):
self.liker.remove(user)
db.session.commit()
return self
def is_like(self, user):
"""
특정 게시물에 좋아요를 눌렀는지에 대한 여부 반환
"""
return (
self.liker.filter(post_to_liker.c.user_id == user.id).count() > 0
)
def get_liker_count(self):
"""
특정 게시물의 좋아요 숫자를 반환
"""
return self.liker.count()
@classmethod
def find_by_id(cls, id):
"""
데이터베이스에서 id 로 특정 게시물 찾기
"""
return cls.query.filter_by(id=id).first()
@classmethod
def find_all(cls):
"""
모든 게시물을 찾음
"""
return cls.query.all()
def save_to_db(self):
"""
게시물을 데이터베이스에 저장
"""
db.session.add(self)
db.session.commit()
def delete_from_db(self):
"""
게시물을 데이터베이스에서 삭제
"""
db.session.delete(self)
db.session.commit()
def update_to_db(self, data):
"""
데이터베이스에 존재하는 게시물을 수정
data = {
"title":"example content",
"content":"example content"
}
형태의 딕셔너리가 들어올 것이라고 가정
"""
for key, value in data.items():
setattr(self, key, value)
db.session.commit()
@classmethod
def filter_by_string(cls, string):
"""
title, content 에 string이 포함되어있는 모든 게시물을 찾음
"""
posts = cls.query.filter(
cls.content.ilike(string) | cls.title.ilike(string)
)
return posts
@classmethod
def filter_by_followed(cls, followed_users, request_user):
"""
현재 사용자가 팔로우한 모든 사람들의 리스트를 받아서,
해당 사람들이 작성한 게시물을 id의 역순으로 정렬하여 리턴
"""
return cls.query.filter(
or_(cls.author == user for user in followed_users + [request_user])
).order_by(PostModel.id.desc())
def __repr__(self):
위처럼 모든 비즈니스 로직들을 model 에 정의하였습니다. 물론 코드가 그리 난해하진 않지만, 비즈니스 로직이 지금보다 복잡해진다면 – model 이 한없이 길어질 수가 있겠죠.
사실은 아직도 이를 “개선해야 하는 것인가?” 에 대해서는 스스로도 잘 판단이 서질 않습니다. 다만, 최종 프로젝트 셋업에서는 이 방법을 바꾸기 위한 시도를 해 봤습니다.
그래서 개선되었던 프로젝트, Money For Rabbit
https://github.com/5nonymous/money-for-rabbit-back
Money For Rabbit 프로젝트는 소중한 팀원들과 함께 진행했던 학교 캡스톤 과목 프로젝트였습니다. 실제로 서비스를 오픈하여 몇십 명이 서로의 마음을 주고받았고, 처음으로 메일 발송 서비스를 사용해 보는 등 새로운 경험을 많이 했던 프로젝트였죠.
위의 프로젝트에서는 몇 가지의 구조 개선이 이루어졌습니다:
.
├── __init__.py
├── config
│ ├── __init__.py
│ ├── default.py
│ ├── prod.py
│ └── test.py
├── db.py
├── ma.py
├── models
│ ├── __init__.py
│ ├── message.py
│ └── user.py
├── resources
│ ├── __init__.py
│ ├── admin.py
│ ├── deploy.py
│ ├── error.py
│ ├── message.py
│ └── user.py
├── schemas
│ ├── __init__.py
│ ├── message.py
│ └── user.py
├── services
│ ├── __init__.py
│ ├── message.py
│ └── user.py
├── static
│ └── css
│ └── login.css
├── templates
│ ├── admin-base.html
│ ├── admin-indexview.html
│ ├── admin-login.html
│ ├── admin-modelview.html
│ ├── email-confirmation-template.html
│ ├── email-send-result.html
│ ├── no-received-alert-template.html
│ └── received-alert-template.html
├── tests
│ ├── __init__.py
│ ├── message_test.py
│ └── user_test.py
└── utils
├── auth.py
├── confrimation.py
├── korean_datetime.py
├── response.py
└── validation.py
그 중 가장 주목할만한 부분은 service layer 가 추가되었다는 것입니다. 사용자의 요청을 최전방에서 받는 resources 코드에서는 진짜 그 계층만이 수행할 수 있는 역할만 수행하고, 실제 비즈니스 로직은 service layer 에서 처리하도록 하자는 것이 그 아이디어였죠. 그렇기에, View 코드들이 아래와 같이 훨씬 간결해진 것을 볼 수 있습니다.
class UserWithdraw(Resource):
"""
회원탈퇴를 처리합니다.
본인만 회원탈퇴를 진행할 수 있습니다.
"""
@classmethod
@jwt_required()
def delete(cls):
"""
클라이언트 -> email, password (로그인과 동일)
"""
data = request.get_json()
user = UserModel.find_by_id(get_jwt_identity())
if not user:
return get_response(False, NOT_FOUND.format("사용자"), 404)
return UserService(user).withdraw(data)하지만 이 코드를 작성하고 나서도 조금은 개선하고 싶었던 부분이 있었는데, 그것들은 아래와 같았습니다.
Service Layer, 정확히 뭘 해야 하나요?
class UserService:
"""
사용자:
- 정보조회
- 정보수정
- 회원가입
- 회원탈퇴
- 로그인
"""
def __init__(self, user=None):
self.user = user
def get_info(self):
return {"user_info": UserInformationSchema().dump(self.user)}
def update_info(self, data):
validate_result = UserInformationSchema().validate(data)
if validate_result:
return get_response(False, validate_result, 400)
self.user.update_user_info(data["username"])
return get_response(True, f"닉네임이 {self.user.username} 으로 변경되었습니다.", 200)
위는 UserService 의 코드 중 일부입니다. __init__() 메서드를 정의했는데, 정의하며 user 객체를 인스턴스로 받고 있네요. 서비스가 “이것은 어떤 사용자에 대한 서비스입니다~” 에 대한 정보를 가지고 있다면 코드를 작성하기 더 쉬울 것이라 생각했기 때문입니다.
그런데 문제점이 생깁니다. 정보조회, 수정, 회원탈퇴, 로그인은 서비스를 이용하는 사람이 누구인지 확실하게 알아야지만 쓸 수 있는 서비스이지만, “회원가입” 의 경우에는 __init__() 메서드에 전달해 줄 user 객체 자체가 존재하지 않습니다. 왜냐하면 회원가입을 해야지만 user 가 데이터베이스에 저장되고, ORM 으로 접근할 수 있으니까요.
물론 동작하는 데에는 문제가 없었지만, “어디까지가 Service Layer 의 역할인가?” 를 정확히 정의해두지 않고 작성하다 보니, 오히려 더 유지보수하기 어려운 코드가 되버린 것 같기도 합니다.
def update_info(self, data):
validate_result = UserInformationSchema().validate(data)
if validate_result:
return get_response(False, validate_result, 400)
self.user.update_user_info(data["username"])
return get_response(True, f"닉네임이 {self.user.username} 으로 변경되었습니다.", 200)특히 위의 코드에서는, 사용자 정보를 수정함과 동시에 “클라이언트에게 어떤 형식으로 응답할 것인가?” 를 Service Layer 에서 정의하고 있습니다. 관심사가 이상합니다. 이러면 “Serivce Layer” 가 아니라 “이도저도 아닌 무언가 Layer” 가 되어 버립니다. “야, 이거 View 가 얇아진 건 좋은데, Service Layer 가 아니라 제 2의 View 아냐?” 라는 질문에 답변하기 창피해져 버린다는 거죠.
새로운 프로젝트에서의 개선된 구조
새로운 프로젝트에서는 아래와 같은 새로운 구조와 레이어들이 추가되었습니다.
Django-Style? app 기반 관심사 분리
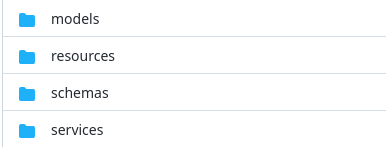
기존의 위와 같은 구조(Money For Rabbit) 에서는 비즈니스 로직이 복잡해지면 그것의 분리를 이끌어내기 어렵습니다. 어떤 주제의 resource 든 resoucres/ 아래에 들어갈 것이고, 어떤 종류의 비즈니스 로직이던 services/ 안에 들어갈 겁니다. (구조에 대해서는 의견이 분분할 수 있겠지만, 저는 그렇게 생각했습니다.)
이번 프로젝트에서는, 프로젝트의 완성뿐만 아니라 유지 및 보수를 용이하게 하기 위해 Django-Style 의 앱 구조를 차용하기로 결정했습니다.
crescendo-backend
├── README.md
├── app.py
├── core
│ ├── __init__.py
│ ├── config
│ │ ├── __init__.py
│ │ ├── default.py
│ │ ├── dev.py
│ │ ├── prod.py
│ │ └── test.py
│ ├── extensions.py
│ ├── factory.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── base_model.py
│ │ └── mixins.py
│ ├── resources
│ │ ├── __init__.py
│ │ ├── marshaller
│ │ │ ├── __init__.py
│ │ │ ├── base_marshaller.py
│ │ │ └── paginate_marshaller.py
│ │ └── parsers.py
│ └── schemas
│ ├── __init__.py
│ └── paginate.py
├── crescendo
│ ├── __init__.py
│ ├── auth
│ │ └── __init__.py
│ ├── circle
│ │ └── __init__.py
│ ├── recruit
│ │ └── __init__.py
│ └── users
│ ├── __init__.py
│ ├── models.py
│ ├── resources.py
│ ├── schemas.py
│ └── services.py
├── db.sqlite3
├── migrations
│ ├── README
│ ├── alembic.ini
│ ├── env.py
│ ├── script.py.mako
│ └── versions
│ └── d7eddb3a7dee_.py
├── requirements
│ ├── default.txt
│ ├── dev.txt
│ └── prod.txt
└── requirements.txt
app.py 가 위치한 곳은 프로젝트의 루트 디렉토리입니다. 간단하게 core/ 에서는 Flask 애플리케이션을 생성하기 위한 application factory 함수와 유틸 파일들이, crescendo/ 폴더 아래에는 각각의 앱들이 위치하고 있습니다. 현재 개발 중이기에 약간 바뀔 수도 있지만, 대략적으로 Django 의 app 기반 디렉토리 구조를 선택한 것입니다. auth, circle, recruit, users 와 같은 앱들에서는 각각 인증, 스터디원 모집, 스터디원 채용, 회원가입과 탈퇴와 같은 역할들을 수행할 겁니다.
클라이언트의 요청을 가장 먼저 환영해주는 곳, resources
먼저, 나름대로의 Resources 의 역할을 확실히 할 필요가 있습니다:
- Resources 에서는, Service Layer 에만 의존해야 합니다.
- Resources 에서는, 클라이언트로부터의 데이터를 받아 검증하고, 알맞는 데이터를 Service 에게 넘겨주어야 합니다.
- Service 에서는 Entity 가 넘어온다고 가정하고, “어떻게 이를 클라이언트 단에게 표현해줄 것인가?” 를 정하는 것은 Resources 의 역할입니다.
@users_api.route("/")
class UserListAPI(Resource):
user_list_marshalling_rule = users_api.model(
**UserMarshaller().to_model(model_name="user_list")
)
def __init__(self, *args, **kwargs):
self.user_service = UserService()
super().__init__(*args, **kwargs)
@users_api.marshal_list_with(user_list_marshalling_rule)
def get(self):
"""사용자 전체 목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_all_users()
def post(self):
"""사용자 한 명을 생성합니다.
비밀번호를 암호화하여 저장합니다."""
return self.user_service.create_user(**request.json)사용자가 /users/ 로 보낸다면, 그것은 우리의 UserList 의 get() 메서드에 닿게 됩니다. 프레임워크 종속적인 부분은 빼고, get() 메서드가 user_service.get_all_users() 메서드를 호출하고 있는 것을 확인할 수 있죠? 마찬가지로 marshalling rule 을 정의하여, 이를 사용해서 service 로부터 반환된 엔티티를 적절하게 마샬링해줄 겁니다. 예시가 너무 조약하고 모든 기능이 구현되지는 않았지만, 이런 흐름을 만들었습니다.
class UserService:
"""회원정보조회, 회원가입, 회원정보수정, 회원탈퇴, 검색"""
def get_all_users(self, **kwargs):
"""모든 사용자 리스트를 반환합니다."""
return User.query.all()그러면 UserService 가 어떻게 구현되어 있는지 알아봅시다. 위와 같이 단지 User.query.all() 만을 반환하고 있네요. (filtering, ordering, pagination 은 아직 구현되지 않았습니다.)
그러면.. 대체 User 는 무엇일까요?
class User(BaseModel, TimeStampedMixin, UUIDMixin):
email = db.Column(db.String(80), unique=True, nullable=False)
username = db.Column(db.String(10), unique=True, nullable=False)
first_name = db.Column(db.String(4), nullable=False)
last_name = db.Column(db.String(4), nullable=False)
gender = db.Column(db.Enum("남자", "여자"), nullable=False)
phone_number = db.Column(db.String(20), unique=True, nullable=False)
password = db.Column(db.String(120), nullable=False)
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
def __repr__(self):
return f"<id:{self.id}, full_name:{self.full_name}>"엇, 이건 Sqlalchemy 모델 클래스네요. 보시다시피 Sevice 는 User Model 에 의존하고 있습니다.
그러면, 또 여기서 고민이 생깁니다.
실제 비즈니스 로직이 처리되는 곳, Services
맞아요. 위의 Service 구현은 철저히 SqlAlchemy ORM 에 의존하고 있습니다. Django 의 경우, Django ORM 이라는 강력한 ORM 이 “Django 프레임워크 단에서” 지원되기 때문에 핏이 잘 맞습니다. 그런데 플라스크는요?
As your codebase grows, you are free to make the design decisions appropriate for your project. Flask will continue to provide a very simple glue layer to the best that Python has to offer. You can implement advanced patterns in SQLAlchemy or another database tool, introduce non-relational data persistence as appropriate, and take advantage of framework-agnostic tools built for WSGI, the Python web interface.
코드베이스가 커짐에 따라 프로젝트에 적합한 설계 결정을 자유롭게 내릴 수 있습니다. Flask는 Python이 제공해야 하는 최고에 매우 간단한 접착 레이어를 계속 제공할 것입니다. SQLAlchemy 또는 다른 데이터베이스 도구에서 고급 패턴을 구현하고, 적절하게 비관계형 데이터 지속성을 도입하고, Python 웹 인터페이스인 WSGI용으로 구축된 프레임워크에 구애받지 않는 도구를 활용할 수 있습니다.
https://flask.palletsprojects.com/en/2.2.x/design/#what-flask-is-what-flask-is-not
Flask 는 위의 공식 문서 소개글, “what flask is what flask is not” 에서 볼 수 있듯이 데이터베이스 추상화 계층을 제공하지 않습니다. 단지 그것을 가능하게 해 주는 Sqlalchemy, Flask-sqlalchemy 와 같은 extension 들이 존재할 뿐이죠. Sqlalchemy 외에도, Python ORM 은 여러 가지가 존재합니다. 어떤 ORM 에서 “데이터베이스에 있는 모든 사용자 데이터를 가져오는 메서드” 는 “멍멍()” 이 될 수도, 다른 ORM 구현에서는 “야옹야옹()” 이 될 수도 있는 노릇이죠.
이러한 문제를 해결하기 위해 저는 Repository pattern 의 도입을 고민하기 시작했습니다. 데이터베이스가 MongoDB 이던, MySQL 이던 – 더 나아가 ORM 의 종류가 무엇이던 Service 는 Repository 에게 데이터를 요청하게끔 하는 거죠. 각각에 맞는 데이터베이스 접근 로직은 Repository 에서 구현한다는 아이디어입니다.
필요한 건 말만 해, Repository
def get_all_users(self, **kwargs):
"""모든 사용자 리스트를 반환합니다."""
return User.query.all()Repository 를 사용할 것이라면 위에서처럼 UserModel 자체를 바로 불러 사용하지 않아야 합니다. 아래처럼 코드가 바뀔 겁니다.
def get_all_users(self, **kwargs):
"""모든 사용자 리스트를 반환합니다."""
return UserRepository.find_all()그러면 Repository 클래스를 또 정의해야겠죠? Repository 를 제가 만든 이유는 ORM 의 변경에 유연하게 대처하기 위함이었구요.
넘겨주는 데이터를 일반화하기 위해서 UserDTO 를 정의하고 있을 무렵.. 이런 생각이 들었습니다.
flask-restx 를 위한 필드 정의하고, 데이터 검증을 위한 marshmallow Schema 에서 필드 정의하고, DTO 를 위한 field 정의하고.. 필드를 몇 번 정의하는 거야?
맞아요. 필드에 대한 정의를 세 번이나 중복해서 하고 있었죠. 마시멜로 스키마를 restx model 로 바꿔주는 메서드부터, pydantic 도입까지.. 이 문제는 잠시 미뤄두기로 했습니다. 프레임워크에 종속적인 문제 말고, 다른 문제가 하나 더 있었기 때문입니다.
명시적으로 의존성 주입하기
Service Layer (Application Layer) 를 도입하며 생긴 Layered Architecture
자연스레 View 함수로부터 비즈니스 로직의 분리를 구현하며, 아래와 같은 레이어가 생기게 되었음을 아셨을 겁니다.
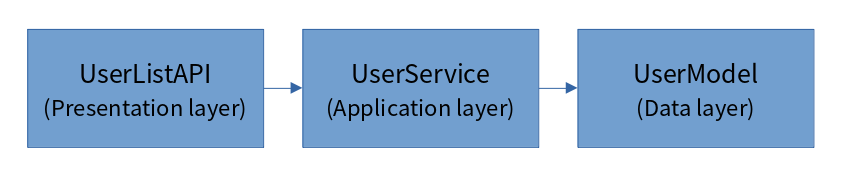
각각은 서로의 역할이 분명히 있습니다. UserListAPI 클래스에서는 HTTP 요청 처리 및 응답을, UserService 에서는 새로운 사용자 생성 및 회원탈퇴 등 비즈니스 로직을, UserModel (ORM 클래스) 에서는 데이터베이스와의 상호 작용을 담당하고 있죠.
그렇기에 UserListAPI 클래스에서는 UserService 를 가져와서 사용하게 됩니다. UserService 객체가 필요한데, 어떻게 적절하게 UserService 를 가져다 쓸 수 있을까요? 제가 처음에 생각했던 코드를 살펴보겠습니다.
의존성 챙기기 시도 1 : Class 밖에서 UserService 인스턴스 생성하기
user_service = UserService()
@users_api.route("/")
class UserListAPI(Resource):
@users_api.marshal_list_with(user_list_marshaller)
@users_api.doc(parser=user_list_parser)
def get(self):
"""사용자 전체 목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return user_service.get_all_users()맨 위에서 UserService 인스턴스를 생성한 다음 가져다가 쓰고 있습니다. 위의 코드의 경우 UserListAPI 클래스를 테스트하기 위해서 별도의 MockService 와 같은 클래스를 생성한 다음 전달해 줄 수도 있고, 나름 괜찮다고 생각했습니다.
하지막 전역 변수를 사용하는 것은 좋지 않은 아이디어처럼 보입니다. 어디서든 user_service 에 접근해서 그것의 상태를 바꿀 수도 있고, UserService() 클래스의 객체를 바꿀 때에는 그것을 가져다 쓰는 모든 곳에서 문제가 생기지 않을지 확인해야 하죠. 요약하면 이를 가져다 쓰는 모든 모듈들과 강력하게 결합되어 있으므로 그리 좋지는 않다는 것입니다.
그럼, 아예 UserListAPI 의 생성자에 넣어버리면 어떨까요? 아래처럼 말이에요.
의존성 챙기기 시도 2 : 생성자에서 UserService 인스턴스 만들기
@users_api.route("/")
class UserListAPI(Resource):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.user_service = UserService()
@users_api.marshal_list_with(user_list_marshaller)
@users_api.doc(parser=user_list_parser)
def get(self):
"""사용자 전체 목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_all_users()Resource 를 다루는 코드네요. resource 계층에서 UserService 를 사용하고 있습니다. __init__() 메서드에서 UserService() 인스턴스를 생성해 멤버 변수로서 저장합니다.
위의 코드의 경우 – UserListAPI 객체가 생성됨과 동시에 UserService() 가 만들어지므로 나중에 테스트를 할 때에 MockService() 와 같은 목 객체를 만들기 어려워집니다. 그러면 당연히 UserListAPI 만 테스트하기 어려워지겠죠. 문제가 생겼을 때, UserListAPI 문제인지, UserService 문제인지를 어떻게 파악할 수 있냐는 겁니다.
의존성 챙기기 시도 3 : 명시적으로 의존성 주입하기
from crescendo.users.marshallers import UserListMarshaller
from crescendo.users.resources import UserListAPI
from crescendo.users.services import UserService
from flask_restx import Namespace, marshal_with
user_service = UserService()
users_api = Namespace(name="UserResource", description="사용자 리소스를 다룹니다.")
user_list_marshaller_model = users_api.model(**UserListMarshaller().to_model_dict())
UserListAPI.get = users_api.marshal_with(user_list_marshaller_model)(UserListAPI.get)
users_api.add_resource(
UserListAPI,
"/",
resource_class_kwargs={
"user_service": user_service,
},
)
이것은 /users/__init__.py 파일의 내용입니다. 위처럼 resource_class_kwargs 에 “user_service” 를 정해주면, UserListAPI 클래스의 생성자에 이것이 주입됩니다. 그래서 아래처럼 get() 메서드에서 서비스 계층을 사용할 수 있죠.
class UserListAPI(Resource):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.api = args[0]
self.user_service = kwargs["user_service"]
print(self.api)
print(self.user_service)
def get(self):
"""사용자 전체 목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_all_users()
실제 생성자에서 찍어보면..
<flask_restx.api.Api object at 0x7f7522f84210>
<crescendo.users.services.UserService object at 0x7f752397aad0>위와 같이 첫 번째 argument 로 API 가, keyword argument 로 UserService 객체가 전달되는 것을 확인할 수 있네요.
그런데 위의 코드, 너무 규격화되지 않은 경향이 있습니다. 지금이야 get 메서드 하나만 다루고 있고, 몇 줄 되지 않아 해석에도 큰 무리가 없지만 만약 등록해야 될 리소스가 늘어난다면 위의 코드를 읽고 해석하기엔 쉽지 않을 겁니다.
의존성 챙기기 시도 4 : welcome, Dependency Injector!
위의 방법을 사용하려면 명시적으로 __init__ 파일 내에서 모든 resources 를 등록해야 합니다. 생성자에 그것들을 전달해주기 위해서 가독성을 잃고 싶지는 않았습니다. flask-restx 프레임워크에서 지원해주는 데코레이터를 사용하여 이것이 어떤 규칙으로 마샬링되고 있는지, 어떤 parser 가 사용되었는지의 책임을 resources.py 파일에게 부여하고 싶었습니다.
그것을 수행하기 위해서 저는 Dependency Injector 모듈을 사용하기로 했습니다.
@users_api.route("/")
class UserListAPI(Resource):
@inject
def __init__(
self,
*args,
user_service=Provide[UserContainer.user_service],
**kwargs,
):
super().__init__(*args, **kwargs)
self.user_service = user_service
@users_api.marshal_with(user_list)
@users_api.param("page", "페이지 번호", type=int, default=1)
@users_api.param("per_page", "페이지당 게시물 수", type=int, default=10)
@users_api.param("filter_by", "검색어", type=str)
@users_api.param(
"ordering", "정렬 조건", type=str, enum=["asc", "desc"], default="desc"
)
def get(self):
"""사용자 전체목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""간단한 공식 홈페이지의 튜토리얼을 사용하여 작성한 코드입니다. @inject 데코레이터를 사용하여 적절하게 UserService 를 주입해주는 것을 알 수 있네요. 아직 DI 프레임워크에 익숙하지 않은 터라, Best Practice 는 잘 모르겠습니다만.. 중요한 건 가독성을 잃지 않으면서, 생성자에 주입하는 방법을 찾아냈다는 겁니다.
주의할 점: 현재
Dependency-Injector는 2024년 2월 5일 기준 업데이트가 진행되지 않고 있습니다.
Flask RESTX -> Flask-Smorest 의 교체
위의 코드를 보면 아시겠지만, REST API 를 구축하기 위해 저는 flask-restx 를 사용하고 있었습니다. 기존 money for rabbit 혹은 flastagram 에서는 flask-restful 을 사용하고 있었지만, swagger 문서를 자동으로 사용하도록 도와준다는 점이 flask-restx 를 사용하도록 하는 제일 큰 이유가 됐죠.
하지만 이 프레임워크를 사용하면서, 몇 가지 문제가 있었습니다.
Flask-RESTX 에서 데이터를 마샬링하는 방법
Flask-RESTX 에서는, 직렬화 및 역직렬화 규칙을 정의하기 위해서 model 이라는 것을 정의해야 합니다. 아래처럼 말이죠:
user = users_api.model(
name="User",
model=dict(
id=fields.Integer(
readonly=True,
example="1",
description="사용자의 데이터베이스 id",
),
uuid=fields.String(
required=True,
example="99cd6b7a-4b22-440a-8671-0c572d06926",
description="사용자의 데이터베이스 uuid",
),
email=fields.String(
required=True,
example="example@example.com",
description="사용자 계정 이메일",
),
username=fields.String(
required=True,
example="goddessana",
description="사용자 닉네임",
),
),
)좋아요. 이렇게 어떻게 데이터를 마샬링해서 보여줄 것인가를 정해줄 수 있고, 이는 Flask-Restx 단에서 OpenAPI 사양으로 바꿔주어 SwaggerUI 와 같은 곳에서 멋지게 렌더링된 API 문서를 보여주게끔 만들어지게 됩니다.
그런데, 위의 코드는 빡센 데이터 검증을 수행해 주지는 않습니다. 예컨대 “이 날짜와 이 날짜 사이에 작성한 내 게시물들을 보여 줘~” 라는 요청을 위해 GET parameter 로 “시작 날짜”, “끝 날짜” 를 받아야 한다면 무조건 “시작 날짜” 는 “끝 날짜” 보다 작거나 같아야 하죠. 위와 같은 필드 레벨에서의 데이터 검증을 수행하기에는 무리가 있었습니다.
그러한 문제점들을 해결하기 위해서, 저는 데이터 검증과 직렬화&역직렬화를 담당해 주는 Marshmallow 의 도입을 고려하게 됩니다.
마시멜로, 달콤해서 너무 좋아!

marshmallow는 객체와 같은 복잡한 데이터 유형을 네이티브 Python 데이터 유형으로 변환하기 위한 ORM/ODM/프레임워크에 구애받지 않는 라이브러리입니다. 사실 Pydantic 과 같은 라이브러리를 도입하고 싶은 마음도 있었지만, 현재는 Marshmallow 라는 라이브러리에 익숙했기 때문에 이를 선택하게 되었습니다.
그러면… 그러면 데이터를 검증하기 위해서 Schema 를 정의해야 합니다. 아래처럼요:
class UserSchema(Schema):
id = fields.Int()
uuid = fields.Str()
email = fields.Str()
username = fields.Str()Marshmallow 에서는 데이터 검증을 위한 풍부한 기능을 제공합니다. 그렇기 때문에 Schema 를 제대로 정의할수록, 클라이언트로부터 들어오는 데이터에 대한 유효성 검증을 빡세게(?) 진행할 수 있다는 장점이 있죠.
그런데 문제가 생깁니다.
결국 모델을 두 번.. 아니 세 번 정의해야 한다.
그러면 데이터를 표현하기 위해서 총 몇 개의 모델을 정의해야 할까요?:
- models.py 의 ORM 모델
- flask-restx 의 모델
- marshmallow 의 Schema
특히나, flask-restx 에서는 많이는 아니지만 – 꽤 기본적인 데이터 검증은 수행할 수 있습니다. 그리고, 결국 OpenAPI 사양은 flask-restx 모델에 의해서 작성되지, Marshmallow 에 의해서 작성되지 않습니다.
결국은 이 곳에서 문제가 생깁니다. 만약 “유효성 검증 규칙의 변경” 이 생기면, 저는 “flask-restx 모델”, “marshmallow 스키마” 두 개의 코드를 변경해야 한다는 거죠. 문서화를 위해서, 실제 데이터 검증을 위해서요. 만약 실수라도 생긴다면 “문서화되어있는 api와, 실제 api 의 유효성 검증 규칙이 일치해버리지 않는” 끔찍한 상황을 맞이할 겁니다.
사실, Flask-Restx 커뮤니티에서 “모델을 재정의하는 것” 은 꽤 오랫동안 논의된 문제인 듯 보였습니다. 아래의 깃허브 이슈에서 그것들을 확인할 수 있죠.
https://github.com/python-restx/flask-restx/issues/59
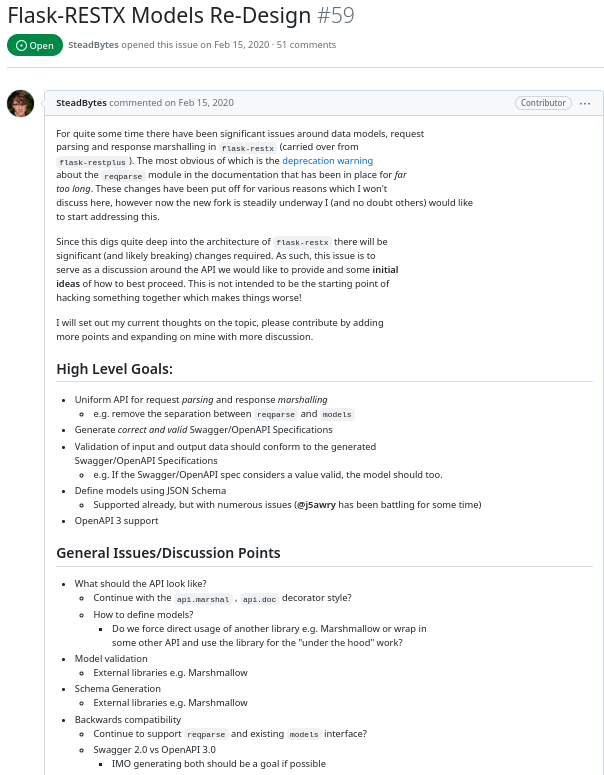
몇 가지가 계속 논의되고 있는 것으로 보이지만, 현재는 모델을 정의하는 것에 있어서 변경을 하지 않고 유지하겠다는 관리자의 의견을 확인할 수 있었습니다:
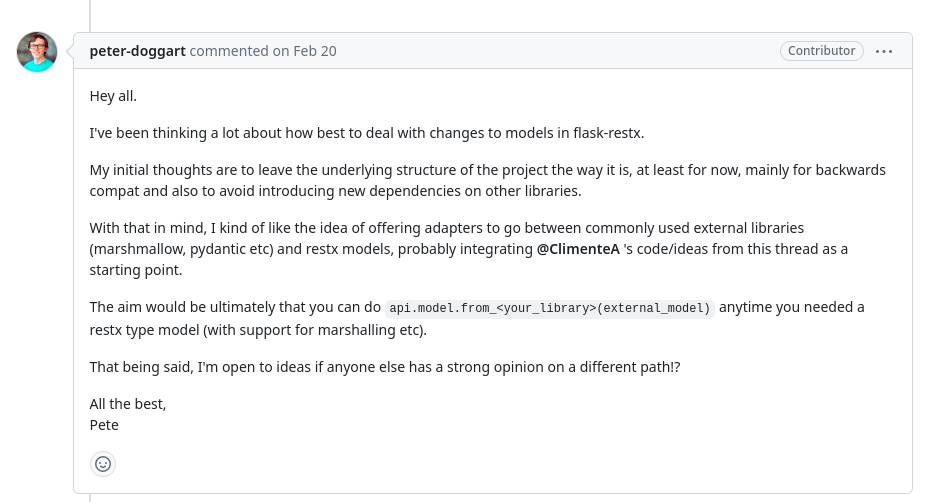
그렇기에, 저는 다른 대안을 찾아나섰습니다. 하나의 모델을 다루기 위해서, 몇 번이나 비슷한 내용을 재작성해야 하는 것은 그리 좋지 않은 방식이라고 느꼈기 때문입니다.
Welcome, Flask-Smorest!
Flask-Smorest 는 Marshmallow 개발자들이 만든 Marshmallow 와 Flask 를 통합해주는 REST API 프레임워크입니다. 적절한 직렬화와 데이터 검증을 Marshmallow Schema 를 통해서 수행하고, 문서화까지 Schema 에서 담당하죠.
저는 이것이 저를 위한 프레임워크라는 것을 느꼈고, 이를 도입하기에 이릅니다. 아래와 같은 스키마를 정의하고 적절하게 사용해 주면, 그것을 검증하는 것은 물론 문서화까지 제대로 해 줍니다.
# 스키마 정의
class ArgsSchema(Schema):
page = fields.Integer(load_default=1)
per_page = fields.Integer(load_default=10)
filter_by = fields.String(load_default=None)
ordering = fields.String(
load_validate=validate.OneOf(["asc", "desc"]), load_default="desc"
)
# 리소스 정의
@users_api.arguments(ArgsSchema, location="query")
@users_api.response(200, UserSchema(many=True))
def get(self, kwargs):
"""사용자 전체목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_list(**kwargs)
아직까지는 이 프레임워크에 만족하고 있는 중입니다. 그러면, 급한 문제가 해결되었으니 또 다른 개선을 진행해 봅시다.
DIP 적용하기
이전의 코드에서는(위에서 구현한 의존성 주입), Resource 가 UserService 의 상세한 구현에 의존하고 있었습니다.
@users_api.route("/")
class UserListAPI(Resource):
@inject
def __init__(
self,
*args,
user_service=Provide[UserContainer.user_service],
**kwargs,
):
super().__init__(*args, **kwargs)
self.user_service = user_service맞아요. 이러면 문제가 생깁니다.
- 상위 모듈은 하위 모듈에 의존해서는 안된다. 상위 모듈과 하위 모듈 모두 추상화에 의존해야 한다.
- 추상화는 세부 사항에 의존해서는 안된다. 세부사항이 추상화에 의존해야 한다.
“위의 코드가 이것을 지키지 않고 있으니 문제가 생긴다..” 와 같은 이야기는 하지 않도록 하겠습니다. 그냥 “위의 코드가 변경사항에 유연하게 대처할 수 있는가?” 를 한번 생각해 볼까요?
맞습니다. UserService 의 구현이 변경된다면, 하위 레이어(Service) 가 변경되었음에도 불구하고 상위 레이어인 Resource 에도 영향을 미치게 되죠.
예를 들어, UserListAPI 는 UserService 의 상세 구현에 의존하고 있습니다. 아래와 같겠죠?
class UserListAPI(MethodView):
# 생략...
@users_api.arguments(ArgsSchema, location="query")
@users_api.response(200, UserSchema(many=True))
def get(self, kwargs):
"""사용자 전체목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_list(**kwargs)
class UserService:
"""회원정보조회, 회원가입, 회원정보수정, 회원탈퇴, 검색"""
def get_list(
self,
page: int,
per_page: int,
filter_by: t.Optional[str],
ordering: str,
):
# 생략..
return result_query(**kwargs)좋아요. 위의 get_list 구현에서 현재는 User (ORM model) 를 반환하고 있다고 가정합시다.
그러면, flask-smorest 의 스키마에 따라 직렬화되어 아래와 같은 응답이 올 겁니다.
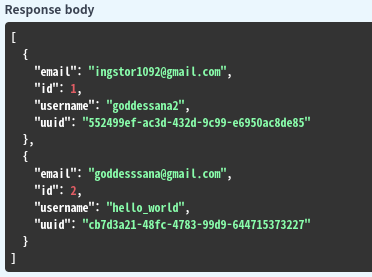
그런데, Service의 구현이 바뀌었습니다. 아래처럼 응답하는 형태가 바뀐 겁니다. 키가 하나 추가되었네요.
return {"users":result_query(**kwargs)}위와 같이 바뀐 경우, 당연히 직렬화가 진행되지 않겠죠?
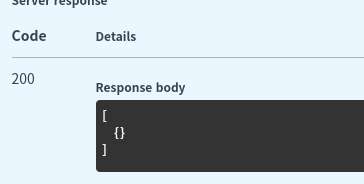
그러면 아래와 같이 Resources 코드도 바뀌어야 합니다. dict 에서 “users” 키를 얻어와 반환하게끔요.
@users_api.arguments(ArgsSchema, location="query")
@users_api.response(200, UserSchema(many=True))
def get(self, kwargs):
"""사용자 전체목록을 조회합니다.
pagination 혹은 filter 결과가 있을 경우도 처리합니다."""
return self.user_service.get_list(**kwargs).get("users")맙소사, 하위 계층이 상위 계층에 영향을 주고 있습니다. 하위 계층의 변경에도 상위 계층은 그 자리를 꿋꿋이 지킬 수 있게 만들어주게끔 하는 방법이 없을까요?
이런 문제를 해결하기 위해서, 인터페이스를 사용할 수 있습니다. 아래의 상황을 예로 들어 생각해 볼까요?
- 핸드폰을 충전하기 위해서는 C타입의 충전기가 필요합니다.
- 충전기는 필수로 C 타입의 규격을 가지고 있어야 합니다.
- 그러면, 어떤 충전기이던, C타입의 규격을 가지고 있다면 핸드폰의 종류에 상관없이 충전을 할 수 있습니다.
위의 예시에서, “핸드폰은 충전기에 의존하고 있다” 를 자연스레 이해하게 되셨을 것이라 생각합니다. 그리고, “C타입” 이라는 규격(인터페이스) 는 “충전기는 무조건 C타입의 형태를 가지고 있어야 한다” 를 강제하게 되는 것이죠.
그러면 위의 상황을 우리에게 적용해 볼까요? 먼저, Service 의 get_list() 가 무조건 flask-sqlalchemy 에서 페이지네이션 된 결과를 반환하도록 합시다.
Python 에서는 사실 인터페이스가 없습니다만, ABC 를 통해서 추상 기본 클래스를 구현할 수 있습니다:
class UserServiceABC(ABC):
@abstractmethod
def get_list(
self,
page: int,
per_page: int,
filter_by: t.Optional[str],
ordering: str,
) -> QueryPagination:
pass좋습니다. UserServiceABC 를 상속받는 모든 클래스들은 page, per_page, filter_by, ordering 을 받아, QueryPagination 객체를 반환해야 합니다. 물론 Python 의 타입 힌트는 코드의 실행에 아무런 영향도 끼치지 않지만, “이것이것을 받아 이것을 반환해야 한다” 를 명시적으로 작성하는 것이라는 점에 의의를 두도록 합시다.
좋습니다. 그러면 이를 구현한 UserService 를 살펴봅시다:
def get_list(
self,
page: int,
per_page: int,
filter_by: t.Optional[str],
ordering: str,
) -> QueryPagination:
query = User.query
# 검색어가 있을 경우 처리
if filter_by:
filter_by = f"%%{filter_by}%%"
query = query.filter(
# username, email 에 검색어가 포함되어 있다면 결과에 나타남
User.username.ilike(filter_by)
| User.email.ilike(filter_by)
)
# 정렬 조건 처리, 기본값은 내림차순인 "desc"
if ordering == "desc":
query = query.order_by(User.id.desc())
elif ordering == "asc":
query = query.order_by(User.id.asc())
# 페이지네이션 처리
return query.paginate(page=page, per_page=per_page, count=True, error_out=False)그런데,, 그런데 말이죠. 지금까지 제 글을 읽어오신 분들은 위의 흐름과 위의 코드가 잘 안 맞는다는 걸 눈치채셨을 겁니다.
맞습니다. UserService 는 UserModel 의 상세 구현에 직접적으로 의존하고 있습니다. 이는 “Service 에서 무조건 SQLAlchemy ORM을 사용하겠다!” 라고 말하는 것과 같죠. 더불어, 이러한 경우 User 모델의 필드에 변경이 생기거나 한다면(하위 레이어인 Model에 변경이 생긴다면 그것에 의존하고 있는 Service 레이어의 코드에도 변경이 필요합니다.
이쯤에서, 저는 선택을 해야 했습니다.
Service 에서 ORM 에 강력한 의존성이 존재해도 되는가?
아래의 구현된 service 코드를 살펴봅시다.
def get_list(
self,
page: int,
per_page: int,
filter_by: t.Optional[str],
ordering: str,
) -> QueryPagination:
query = User.query
# 검색어가 있을 경우 처리
if filter_by:
filter_by = f"%%{filter_by}%%"
query = query.filter(
# username, email 에 검색어가 포함되어 있다면 결과에 나타남
User.username.ilike(filter_by)
| User.email.ilike(filter_by)
)
# 정렬 조건 처리, 기본값은 내림차순인 "desc"
if ordering == "desc":
query = query.order_by(User.id.desc())
elif ordering == "asc":
query = query.order_by(User.id.asc())
# 페이지네이션 처리
return query.paginate(page=page, per_page=per_page, count=True, error_out=False)맞습니다. 위의 부분에서는 Service 가 데이터에 접근하는 것까지 처리하고 있습니다.
앞서 저는 제 애플리케이션의 구조를 위와 같이 제시했습니다. 그렇게 하며 설명을 덧붙였죠 : UserModel 클래스(ORM model) 에서 데이터베이스와의 소통을 담당한다구요.
하지만 위의 구조에서는 몇 가지 문제가 생길 수 있습니다:
- 위의 구조처럼 ORM 을 서비스 레이어에서 직접 사용한다면, 서비스 레이어는 특정 ORM 의 구현에 강력하게 의존하게 됩니다. 그 말은, 만약 ORM 의 교체가 일어날 경우 서비스 레이어의 코드에도 큰 변경이 있어야 한다는 것이죠.
- 테스트를 작성하기 어려워집니다. 만약 Service Layer 를 테스트한다면, 그것은 orm 에 강력하게 의존하고 있으므로 “서비스 레이어” 를 테스트함에도, “ORM 이 정상적으로 동작한다는 것”, “Model 에 문제가 없을 것” 과 같이 다른 레이어에 대한 의존성이 생기게 됩니다.
그리하여 저는 아래와 같이, Repository Pattern 의 도입을 다시금 고민하기 시작했습니다:
Welcome back, Repository!

맞습니다. 위에서는 UserRepository 라는 계층이 하나 추가되었습니다. Repository 는 데이터를 가져오는 역할을 합니다. 이 데이터가 Sqlite 에서 온 것이든, Oracle 에서 온 것이든, 심지어 in-memeory 에서 온 것이든 말이에요. 위에서 설명했듯, “어떤 데이터가 필요하던간에 나한테 말만 해!” 가 되는 거죠. 위의 다이어그램에서의 UserService 는 데이터가 필요하다면 UserRepository 에서 요청만 하면 될 뿐이지, “어떤 ORM 을 사용하지?” “페이지네이션을 하기 위해서 ORM 의 어떤 메서드를 사용해야 하지?” 와 같은 것을 알 필요가 없습니다.
좋아요. 이제 진짜 그것을 도입해 봅시다. 프레임워크의 변경이 있었으므로 모델의 재정의에서도 자유로워졌습니다!
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
from flask_sqlalchemy.pagination import QueryPagination
from flask_sqlalchemy.query import Query
from core.extensions import db
from crescendo.users.models import UserModel
class UserRepositoryABC(ABC):
@abstractmethod
def read_one_by_uuid(self, uuid: str):
pass
@abstractmethod
def read_list(
self, page: int, per_page: int, filter_by: str, ordering: str
) -> dict[str, int | list[Any]]:
pass
@abstractmethod
def delete(self, model):
pass
@abstractmethod
def save(self, model):
pass
class UserRepository(UserRepositoryABC):
def __init__(self):
self.user_model = UserModel
def _get_base_query(self) -> Query:
return self.user_model.query
def read_one_by_uuid(self, uuid) -> Optional[UserModel]:
return self.user_model.query.filter_by(uuid=uuid).first()
def read_list(
self, page: int, per_page: int, filter_by: Optional[str], ordering: str
) -> dict[str, int | list[Any]]:
query = self._get_base_query()
if filter_by:
query = self._filter_by(query, filter_by)
query = self._order_by(query, ordering)
result = self._paginate(query, page, per_page)
return dict(
current_page=result.page,
per_page=result.per_page,
total_page=result.pages,
results=result.items,
)
def _filter_by(self, query: Query, filter_by: str) -> Query:
filter_by = f"%%{filter_by}%%"
return query.filter(
self.user_model.username.ilike(filter_by)
| self.user_model.email.ilike(filter_by)
)
def _order_by(self, query: Query, ordering: str) -> Query:
if ordering == "desc":
return query.order_by(self.user_model.id.desc())
elif ordering == "asc":
return query.order_by(self.user_model.id.asc())
else:
return query
def _paginate(self, query: Query, page: int, per_page: int) -> QueryPagination:
return query.paginate(page=page, per_page=per_page, count=True, error_out=False)
def delete(self, model: UserModel) -> UserModel:
with db.session.begin():
db.session.add(model)
return model
def save(self, model: UserModel) -> UserModel:
with db.session.begin():
db.session.add(model)
return model
repository 는 위와 같이 구성할 수 있습니다. 현재 repository 구현에서는 model object 를 반환할 겁니다. 다만, 페이지네이션의 경우 SQLALchemy의 QueryPaginate 객체를 반환하게 되어 있으므로, 이를 적절하게 매핑하여 딕셔너리를 반환하겠습니다.

그러면 위와 같이 Service 코드는 데이터를 가져오는 부분은 repository 에만 맞기면 그만입니다. 물론 repository 는 생성자로부터 주입되므로, 테스트 시 FakeRepository 와 같은 테스트용 repository 를 만들어 Service Layer 만 테스트를 할 수 있겠죠?
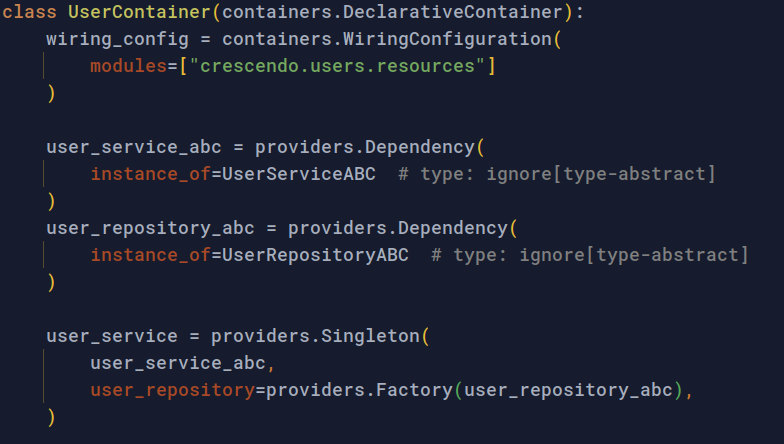
이곳에도 물론 DIP 를 적용해주었습니다. UserRepository 는 무조건 UserRepositoryABC (인터페이스) 를 상속받아 만들어져야 합니다!
그러면, 현재 구현한 요청의 흐름을 살펴볼까요?
구현한 API 살펴보기 : 시작부터 끝까지

요청을 보냅니다. 적절한 페이지네이션 querystring 과 함께요.
해당 요청은, Flask 의 application factory 에서 정의된 blueprint 에 따라 users_api 의 resource 계층에 도달합니다.
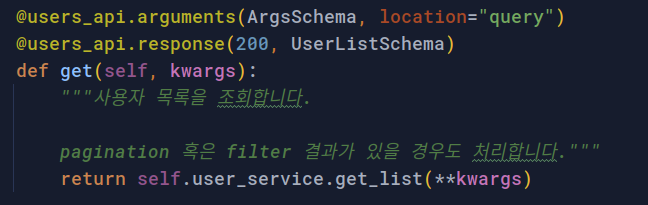
그리고 resource 에서 – @arguments 데코레이터에 의해 쿼리스트링에 대한 유효성 검증을 수행합니다. 만약 쿼리스트링이 유효하다면, 다음 단계로 넘어갑니다. 바로 Service Layer 이죠!

Service Layer 에서는, 해당 요청을 완료하기 위해서 데이터를 가져오는 책임을 Repository Layer 에게 묻습니다.
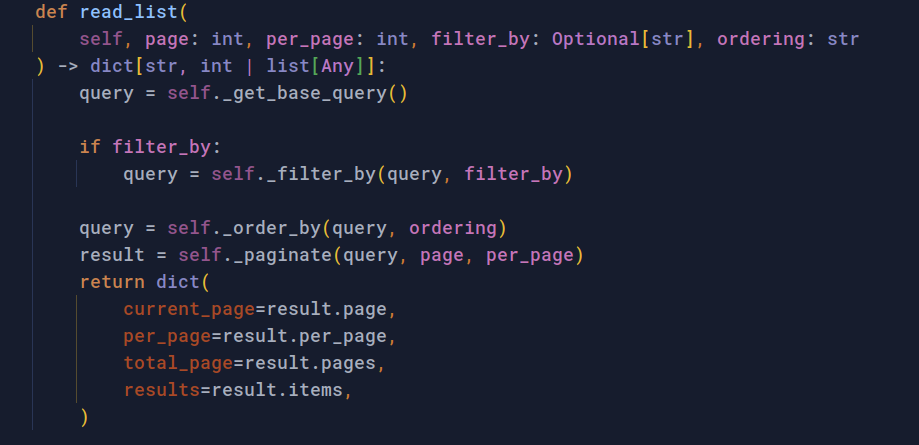
Repository Layer 는 Sqlalchemy 가 제공하는 쿼리 메서드들을 통해 적절한 데이터를 가져와 반환합니다.
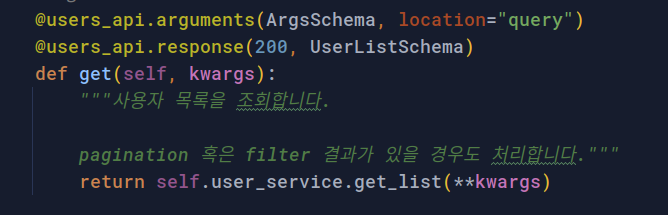
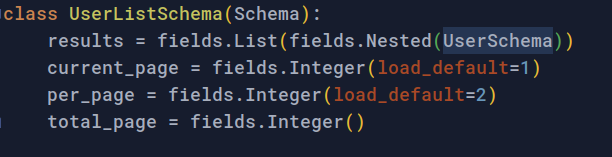
resources 계층으로 반환된 데이터는 @response 데코레이터에 의해, UserListSchema 의 규칙대로 직렬화되어 클라이언트에게 응답합니다. UserListSchema 는 아래와 같이 생겼습니다.
그리고, @response 데코레이터의 내부를 살펴보면 아래와 같이 스키마를 이용해 직렬화한 다음, jsonify 를 이용하여 응답을 만들어내는 것을 확인할 수 있죠!
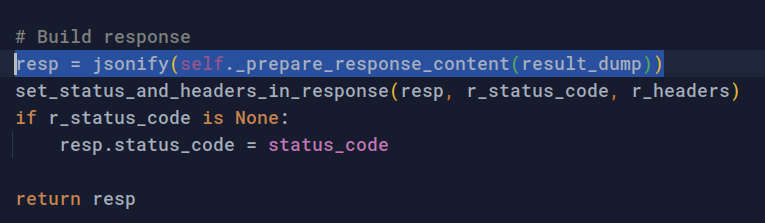
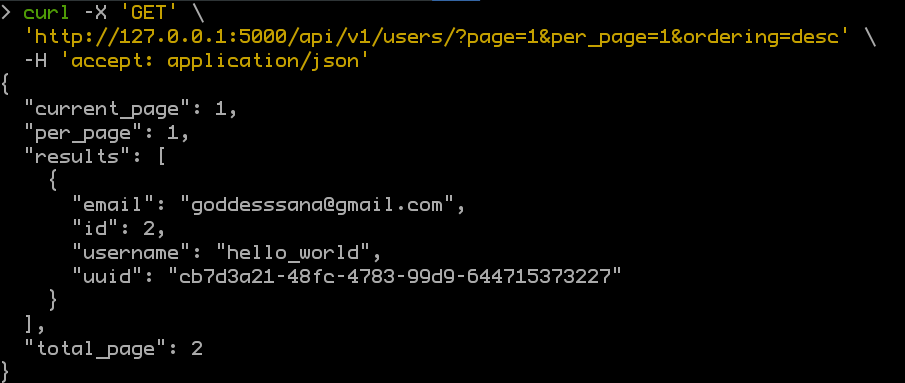
결국, 사용자는 아래의 응답을 받게 됩니다.
되돌아보며
YAGNI : You aren’t gonna need it
어쩌면, 위에서 구현한 아키텍쳐와 구조들이 오버엔지니어링일 수도 있습니다. 실제로 위의 길고 긴 여정에서 제대로 구현된 것은 “사용자 목록에 대한 목록 조회” 였을 뿐이죠.
하지만, 위처럼 많은 삽질과 키워드들을 얻고 – 내가 모르는 것이 무엇인지를 얻고, 그것을 직접 내 손으로 구현해 보며 얻은 것들도 많았다고 생각합니다.
앞으로는 위의 구조를 따르며 복잡한 요구사항을 가진 어플리케이션을 작성하는 과정을 계속 진행해볼까 합니다. 간단한 요구사항일 때를 가정하고 만든 것이 아닌, “과연 복잡한 요구사항을 가진 Flask 어플리케이션은 어떻게 구조를 쌓는 게 좋을까?” 에서 시작한 프로젝트이기 때문입니다. (하지만 위의 개념들은 중 대부분은 Flask 뿐만 아니라 프레임워크에 종속받지 않는 것들이었죠.)
남은 또 하나의 삽질: Test Code
아직 테스트 코드를 작성하지는 않았는데, 과연 위의 구조를 따를 때 테스트 코드 작성이 용이해지는지도 궁굼한 부분이었습니다. 앞으로는 기능 구현을 하며 테스트 코드에 대한 작성도 빼놓지 않으려고 합니다.
결과적으로 위에서 구축한 애플리케이션의 구조가 현실 세계의 복잡한 문제와 개발의 용이성 두 마리 토끼를 잡는 해결책이 되었으면 좋겠습니다. 물론 어떤 선택을 하던 그것에 대한 마이너스와 플러스가 있습니다. 그것을 잘 재 보고 선택을 하는 것 뿐이죠. 그리고 적어도 이렇게 삽질하는 경험을 한 저의 선택은 옳았다고 생각합니다. 구현한 아키텍쳐가 제대로 된 것이든, 오버엔지니어링이든 , 그냥 이것저것 하고 싶었던 초보 개발자의 객기일 뿐이든 말입니다.
긴 글 읽어주셔서 감사합니다!
