[Flask] – “python에서 궁극의 Repository 구현하기”
[Flask] – “python에서 궁극의 Repository 구현하기”
쓸데없이 반복되는 코드는 개발자를 화나게 해요!
이는 제가 고민한 점과 해결한 방법을 작성한 것일 뿐 전혀 BEST PRACTICE 가 아닐 수 있습니다. 더 우아한 방법이 생각나신다면 그것을 알려주세요..!
Blog-Driven-Development 는 전혀 추천하는 방법이 아닙니다.

결국엔, 이거를 해결하는 과정입니다. 아래 글을 읽고 오시면, 제 삽을 더 잘 이해하실 수 있습니다.
이전 글에서 어떻게 Flask 프로젝트를 구성할 것인지에 대해서 고민하고, 그것의 결론으로 Repository pattern 을 사용하기로 결정했었습니다. 그리고 그것의 결과로 위의 포스팅에서 간단한 목록 조회 메서드를 제시했었죠.
현재 저는 SQLAlchemy 를 ORM 으로서 이용하고 있습니다. 그리고, 다른 앱(위 글에서의 django-style 기반 관심사 분리 목차 참고) 에서도 그것을 사용할 것입니다.
from abc import ABC, abstractmethod
from typing import Optional
from flask_sqlalchemy.pagination import Pagination
from flask_sqlalchemy.query import Query
from core.entities.pagination import PaginationEntity
from core.extensions import db
from crescendo.auth.entities import UserEntity
from crescendo.auth.models import UserModel
class UserRepositoryABC(ABC):
@abstractmethod
def read_one_by_uuid(self, uuid: str) -> UserEntity:
"""생략..."""
@abstractmethod
def read_one_by_email(self, email: str) -> UserEntity:
"""생략..."""
# 기타 다른 메서드들...
class SQLAlchemyUserRepository(UserRepositoryABC):
"""구현체... 내용은 생략..."""이것이 구현된 UserRepositoryABC(인터페이스) 와 UserRepository 구현체였습니다. 인터페이스(Python 에서의 추상 클래스이므로, 앞으로 추상 클래스라고 부르겠습니다.) 단에서 각각의 메서드가 반환하는 타입을 UserEntity 로 주는 것을 볼 수 있습니다.
class UserRepositoryABC(ABC):
@abstractmethod
def read_one_by_uuid(self, uuid: str) -> UserEntity:
"""
UUID 로 특정할 수 있는 사용자 엔티티를 반환합니다.
:param uuid: 사용자 UUID
:return:
"""
pass추상 클래스를 정의하고, 그것의 구현체에 의존하는 다른 계층에서 추상 클래스에게 의존하도록 이전 글에서 구현했었습니다. 그렇기에 repository 계층을 사용하는 다른 계층에서는, 그것의 구현체가 무엇이든간에 추상 클래스를 준수하기만 하면 되었으므로 각각의 계층 간에 낮은 결합도를 구현할 수 있었습니다.
좋아요 – 위의 경우까진 좋습니다. 다만 위의 로직들은 어디서든 반복될 수 있는 로직들입니다. 간단하게 CRUD 만 다루는 로직들이기에, 그리고 추상 클래스의 구현체가 SqlAlchemy 를 사용하기에 – 생성하고, 조회하고, 수정하고, 삭제하는 대상만 달라질 뿐 기본 구현은 비슷하다는 것이죠.
그러므로, “달라지는 것” 과 “달라지지 않는 것” 을 구분하여 “달라지지 않는 것” 을 묶어 어디서든 사용할 수 있도록 repository 를 구현하도록 해 보겠습니다.
Step 01. Repository 에서 필요한 것은 무엇인가?
“모든 Repository 에서 공통적으로 사용될 것만 같은, 흔히 사용되는 것들을 미리 정의해두자” 를 달성하기 위해서는 “흔히 사용되는 것들은 과연 무엇인가?” 를 먼저 알아봐야 합니다. 그리고 일반적으로 이런 상황에서는 다른 사람들이 미리 어떻게 문제를 해결했는지를 살펴보는 것이 도움이 됩니다. 그리고 살펴볼 예시가 꾸준히 유지&보수되고, 가능한 많이 쓰이는 프로젝트라면 더더욱 좋겠죠. 이 두 조건을 모두 만족하는 프로젝트가 있습니다. 바로 JavaScript 진영의 Nest.js, 그리고 Java 진영의 Spring Data JPA 입니다.
Nest.js 는 이러한 문제를 어떻게 해결하는가? (feat. TypeORM)

Nest.js 는 서버 측 애플리케이션을 구축하기 위한 백엔드 프레임워크입니다. 기본적으로 Express.js 위에 구축되었으며, TypeORM 을 데이터베이스와의 소통의 도구로서 활용하죠. Nest.js를 참고할 만한 예시로 선정한 것은 TypeORM 때문이었습니다. 그것이 Repository Pattern 을 지원하기 때문입니다.
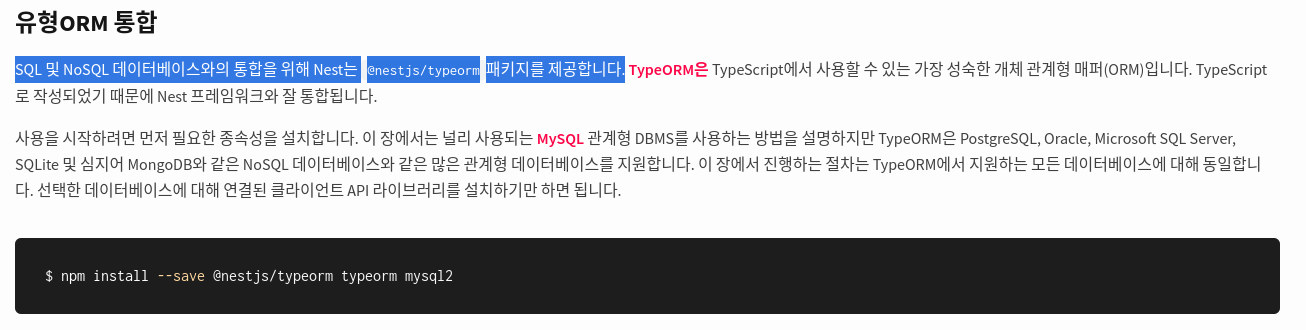
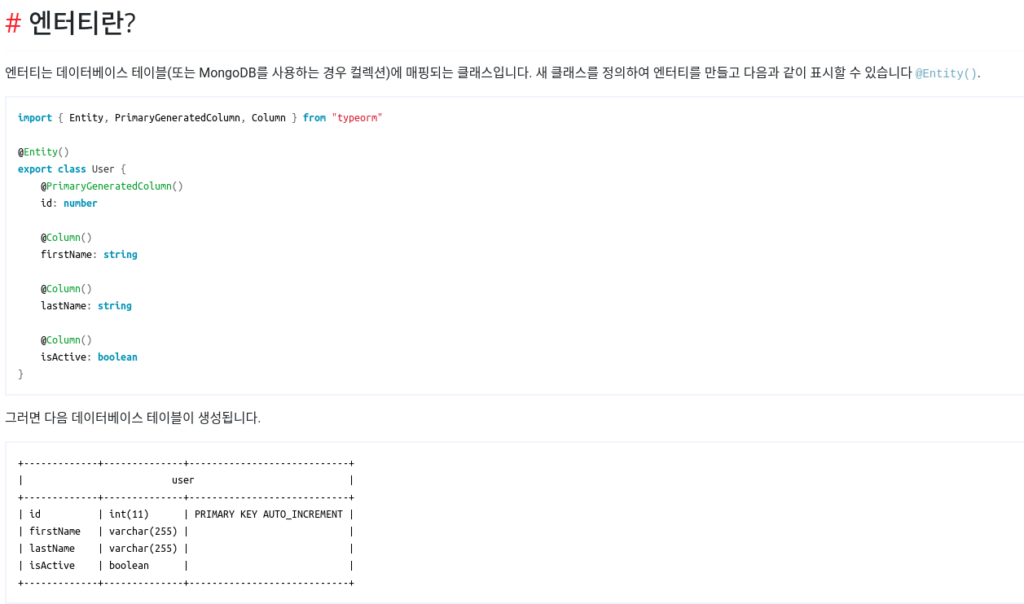
데이터베이스 테이블에 매핑된 하나의 클래스를 엔티티라고 부르는데, 아래의 예시를 보면 이해가 쉬울 겁니다. (Django 를 경험해보신 분들이라면 이것이 models.py 안에 들어있을 법한 코드라는 것을 알아차리셨을 것입니다.)
TypeORM 의 Entity 는 프로그래머가 어떤 방법을 사용하느냐에 따라 멍청해질 수도, 똑똑해질 수도 있습니다. TypeORM 은 Active Record Pattern 과 Data Mapper 패턴을 모두 지원하기 때문입니다. 간단하게 두 패턴 간 사용의 차이점은 아래와 같습니다.
// User 엔티티를 정의하자.
import { BaseEntity, Entity, PrimaryGeneratedColumn, Column } from "typeorm"
@Entity()
export class User extends BaseEntity {
@PrimaryGeneratedColumn()
id: number
@Column()
firstName: string
@Column()
lastName: string
@Column()
isActive: boolean
}
// 새로운 User 엔티티를 저장해 보자!
const user = new User()
user.firstName = "Timber"
user.lastName = "Saw"
user.isActive = true
await user.save()
// User 엔티티를 삭제해 보자!
await user.remove()
// User 엔티티 정보를 조회해 보자!
const users = await User.find({ skip: 2, take: 5 })
const newUsers = await User.findBy({ isActive: true })
const timber = await User.findOneBy({ firstName: "Timber", lastName: "Saw" })위의 방식은 Active Record 패턴 사용의 예시입니다. 위의 방식에서 User 는 엔티티인데, 엔티티에서 직접적으로 save() 메서드나 remove(), find() 와 같은 메서드를 호출하는 것을 확인할 수 있죠. 이는 위의 예제에서 User 엔티티가 BaseEntity 메서드를 확장했기 때문입니다. 실제 Nest.js 의 BaseEntity 소스 코드의 일부는 아래와 같습니다. save(), remove(), 메서드가 정의되어 있는 것이 보이시죠? 내부적으로는 getRepository 메서드를 사용해서 작업을 수행하는 것을 알 수 있네요.
export class BaseEntity {
hasId(): boolean {
const baseEntity = this.constructor as typeof BaseEntity
return baseEntity.getRepository().hasId(this)
}
save(options?: SaveOptions): Promise<this> {
const baseEntity = this.constructor as typeof BaseEntity
return baseEntity.getRepository().save(this, options)
}
remove(options?: RemoveOptions): Promise<this> {
const baseEntity = this.constructor as typeof BaseEntity
return baseEntity.getRepository().remove(this, options) as Promise<this>
}
// 이하 생략...
static find<T extends BaseEntity>(
this: { new (): T } & typeof BaseEntity,
options?: FindManyOptions<T>,
): Promise<T[]> {
return this.getRepository<T>().find(options)
}
static findBy<T extends BaseEntity>(
this: { new (): T } & typeof BaseEntity,
where: FindOptionsWhere<T>,
): Promise<T[]> {
return this.getRepository<T>().findBy(where)
}얼핏 보면 Active Record 패턴의 사용 예시는 django 의 것과 굉장히 유사합니다. 아래의 예시처럼요!
from django.contrib.auth.models import User
def create_user(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
email = request.POST.get('email')
user = User.objects.create_user(username=username, password=password, email=email)
# Additional fields like first name, last name, etc. can be set here
user.save()
# Redirect or return a response
이 곳에서도 user.save() 처럼, Django model 의 메서드를 직접 호출하여 데이터베이스와의 소통을 담당하고 있는 것을 알 수 있습니다. 하지만, 이것은 우리의 사용 사례가 아닙니다. 우리가 하고자 하는 건, Entity 를 얇게 유지하고, Repository 안에서 데이터에 접근하는 겁니다.
TypeORM 에서는 이와 같은 사용 사례에 걸맞는 Data Mapper 패턴을 지원합니다. TypeORM 에서 제공하는 Data Mapper 패턴의 사용 사례는 아래와 같습니다.
import { Entity, PrimaryGeneratedColumn, Column } from "typeorm"
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column()
firstName: string
@Column()
lastName: string
@Column()
isActive: boolean
}
const userRepository = dataSource.getRepository(User)
// 새로운 User 엔티티를 저장해 보자!
const user = new User()
user.firstName = "Timber"
user.lastName = "Saw"
user.isActive = true
await userRepository.save(user)
// User 엔티티를 삭제해 보자!
await userRepository.remove(user)
// User 엔티티를 조회해 보자!
const users = await userRepository.find({ skip: 2, take: 5 })
const newUsers = await userRepository.findBy({ isActive: true })
const timber = await userRepository.findOneBy({
firstName: "Timber",
lastName: "Saw",
})맨 위의 글, “어떻게 Flask 프로젝트를 구성할 것인가?” 를 읽어보셨다면 위의 사용 사례가 더 익숙하실 것입니다. Repository 라는 클래스 내에서 find(), remove() 와 같은 메서드를 사용하여 데이터를 다루는 것을 확인할 수 있죠.
생각해 보면 위의 소스코드가 신기합니다. 위에서 Repository 를 가져오는 코드는 const userRepository = dataSource.getRepository(User) 뿐입니다. 그리고 그것을 가져왔을 뿐인데, find() 와 같은 메서드를 자유자재로 사용하고 있습니다. 그것은 필히 getRepository 로 얻어지는 Repository 클래스 내에 그것들이 모두 구현되어 있다는 것을 의미합니다.
https://github.com/typeorm/typeorm/blob/master/src/repository/Repository.ts
그리고 TypeORM 의 기본 Repository 에 대한 구현은 위와 같습니다. 간단하게 살펴보자면, 아래의 메서드들이 있네요.
- hasId
- getId
- create
- merge
- preload
- save
- remove
- softRemove
- recover
- insert
- update
- upsert
- delete
- softDelete
- restore
- exist
- count
- countBy
- sum
- average
- minumum
- maximum
- find
- findBy
- findAndCount
- findAndCountBy
- findByIds
- findOne
- FindOneBy
- …기타 등등
좋아요, TypeORM 에서는 위의 것들을 사용하네요. 위의 메서드들을 머릿속에 잘 넣어두고, 다음 모범 사례로 넘어가보도록 합시다.
Spring Data JPA 의 JPARepository 는 이러한 문제를 어떻게 해결하는가?
저는 Spring Data JPA 의 JPARepository 를 학교에서 스터디를 할 때 한 번 써 봤습니다. 그 때에는 Repository Pattern 에 대해서 익숙하지도 않을 때였지만, JPARepository 코드 몇 줄이 주는 기능들은 “마법” 이라고 생각될 만큼 신기했죠.
애플리케이션에서 데이터 액세스 계층을 작성하는 것은 꽤 오랫동안 번거로운 일이었으며 그러한 번거로운 일들은 계속 반복되는 작업이었습니다. Spring Data JPA 는 “개발자로서 필요한 만큼만 노력해, 나머지는 내가 다 처리할게!” 라는 목적 아래 개발되었습니다. 그렇기 때문에 아래의 코드만으로도 기본적인 CRUD 를 처리하는 것이 가능하고, 메서드명에 따라서 원하는 쿼리를 작성할 수 있죠.
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
User findByUsername(String username);
List<User> findByAgeGreaterThan(int age);
}
위의 것은 마법처럼 보이지만 실제로 컴퓨터에서 마법은 존재하지 않습니다. 개발자가 피땀흘려 작성한 코드가 존재할 뿐이죠. 위의 JPARepository 코드가 마법처럼 모든 것을 처리해주는 착각을 불러일으키는 이유를 간단하게 알아봅시다.
JPA: 마법이 시작되는 곳
마법은 JPA 부터 시작됩니다. JPA 는 Java Persistence API 의 약자로서, Java 개체를 관계형 데이터베이스 테이블에 매핑하고 객체 지향 프로그래밍 개념을 사용하여 데이터베이스 작업을 수행하는 표준 방법을 제공하는 Java 사양입니다.
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String email;
public User() {
}
public User(String username, String email) {
this.username = username;
this.email = email;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
위의 코드는 User 테이블을 나타내는 JPA 엔티티 코드입니다. 위의 Nest.js 의 것과 굉장히 유사하죠? 다만 차이점은 TypeORM 의 경우 TypeScript 코드가 데이터베이스 테이블을 대표하는 방식을 본인들만의 것으로 정했다는 거고, 위의 코드의 경우에는 User 테이블을 Java 코드가 대표하는 방식이 정해져 있다는 겁니다. 그것을 바로 JPA 라고 부르는 것이구요. 이는 Python 진영과 다른 점을 제공하는데, Python 에서는 JPA 와 같은 스펙이 없기에 어떤 ORM Framework 를 사용하느냐에 따라서 작성해야 하는 코드기 달라지기 때문입니다. 아래의 코드를 살펴봅시다:
from django.db import models
class User(models.Model):
username = models.CharField(max_length=255)
email = models.EmailField(unique=True)
password = models.CharField(max_length=255)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
#############################################################
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
username = Column(String(255))
email = Column(String(255), unique=True)
password = Column(String(255))
created_at = Column(DateTime, default=datetime.datetime.utcnow)
updated_at = Column(DateTime, default=datetime.datetime.utcnow, onupdate=datetime.datetime.utcnow)
위의 코드를 살펴보면 Django ORM 을 사용하느냐, SQLAlchemy 를 사용하느냐에 따라서 작성해야 하는 코드가 달라짐을 알 수 있습니다. 그렇기 때문에 개발자는 사용하고자 하는 프레임워크의 API 를 모두 학습해야 하죠. 그것은 테이블을 순수한 Java 문법으로 나타낼 수 있는 것과 달리, Python 에서는 프레임워크 종속적인 코드가 되어버린다는 것도 의미합니다. “사용자 테이블을 어떤 외부 프레임워크나 라이브러리를 사용하지 않고 코드로 나타내 보아라” 가 불가능하다는 겁니다.
Spring Data project: 상용구 제거 마법을 부리는 곳
JPA 사양을 사용한다고 해도, 그것을 이용하여 Repository 를 구성하는 것은 꽤 많은 상용구 코드를 필요로 합니다.
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import javax.persistence.TypedQuery;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public class UserRepository {
@PersistenceContext
private EntityManager entityManager;
public User findById(Long id) {
return entityManager.find(User.class, id);
}
public void save(User user) {
entityManager.persist(user);
}
public User update(User user) {
return entityManager.merge(user);
}
public void delete(User user) {
entityManager.remove(user);
}
public List<User> findAll() {
TypedQuery<User> query = entityManager.createQuery("SELECT u FROM User u", User.class);
return query.getResultList();
}
}
위의 코드에서의 메서드를 보면 거의 모든 Repository 에서 사용할 법한 메서드들이 구현되어 있는 것을 확인할 수 있습니다. 그에 맞는 에러 핸들링 코드들도 말이죠. JPA 를 사용한다고 해도 위의 것은 꽤 복잡합니다. 만약 다른 엔티티에 대한 Repository 를 구성해야 한다면, 개발자는 위의 코드들을 또 다시 사용해야 하죠. 위의 구현은 사실 완벽하지 않습니다. 예를 들면 save() 메서드는 저장하고자 하는 메서드가 새 것인지 아닌지를 판단해야 합니다. 또, findById() 메서드처럼 ID 를 이용해서 무언가를 수행하려면 ID 는 Null이 아니어야 한다는 보장도 필요하고, 만약 Null 이 들어온다면 적절한 에러를 발생시켜야 하죠. 그리고 이 모든 것들은 프로그래머의 몫이었습니다.

Spring Data JPA 는 위의 문제를 해결하고자 하는 목적으로 개발되었습니다. 그렇기 때문에 위의 JPARepository 의 예시처럼 코드의 절대적인 양이 엄청 줄어드는 결과를 내놓을 수 있었죠. 그리고 save() 와 같은 메서드들은 다음과 같이 구현되어 있습니다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}이처럼 Spring data JPA 는 CRUD 와 같은 상용구들을 미리 구현해 놓음으로서 개발자의 역할을 크게 줄입니다. 크게 보면 JPARepository 는 아래의 메서드들을 가지고 있습니다.
- delete
- deleteall
- findone
- getone
- exists
- findall
- count
- save
- flush
- readpage
- getQuery
좋아요, 위의 TypeORM 의 경우와 비슷한 메서드들을 지원하는 것 같아 보입니다. 위의 좋은 예시들을 참고해서, 우리만의 Repository 를 만들어봅시다.
Step 02. SQLAlchemy 를 이용한 Repository 만들기
ORM 구현 선택하기
위에서 언급했듯, Python 진영에는 JPA 와 같은 엔티티에 대한 표준 스펙이 존재하지 않습니다. JPA 와 같은 방대한 내용의 스펙을 새로 작성할 것이 아니라면 ORM 구현체를 골라 이용하는 것이 적절해 보입니다.
결과적으로는 SQLAlchemy 를 사용하겠습니다. 이유는 현재 개발함에 있어 익숙하다는 것이 가장 큽니다. 또한 SQLALchemy 가 Python 생태계에서 peewee 보다 더 많이 사용된다는 느낌도 한 몫을 했습니다. 둘 다 모두 꾸준히 유지보수되는 프로젝트이지만, FastAPI 공식 문서의 튜토리얼에서도, 그리고 대부분의 검색에서도 SQLAlchemy 를 주로 사용하는 것을 많이 보았기 때문인 듯합니다.
Repository 라면 이 정도는 가지고 있어야지! Python 추상 클래스 정의하기
아무튼, 그러면 우리는 구현을 할 수 있습니다. Service Layer 에서, 우리가 만들 Repository 는 아래와 같이 사용될 겁니다.
이전에 작성했던 글 https://www.gdsanadevlog.com/planguages/real-python-flask-%ec%96%b4%eb%96%bb%ea%b2%8c-flask-%ed%94%84%eb%a1%9c%ec%a0%9d%ed%8a%b8%eb%a5%bc-%ea%b5%ac%ec%84%b1%ed%95%a0-%ea%b2%83%ec%9d%b8%ea%b0%80/ 에서는 Entity 라는 이름의 dataclass 와 ORM class 를 분리했습니다. 다만 애플리케이션 전체에서 SQLAlchemy 에 의존성이 존재하게끔 하기로 결정했는데, 이유는 아래와 같습니다.
python dataclass 와 sqlalchemy 의 완벽한 통합을 이루기에는 python 에서 제공하는 JPA 와 같은 표준 사양이 없기에 불가능하거나 너무나 많은 시간이 필요했습니다. 예컨대 dataclass 에
id: int와 같은 코드가 있다면 dataclass 에서 그것을 sqlalchemy 모델 클래스로 바꾸어 주는 작업이 필요했는데,pk여부 등을 판별하여sqlalchemy로 전달해 주려면 적어도 그것을 관장하는 표준 사양 정도는 존재해야 했습니다. 하지만 sqlalchemy 에서 제공하는 API 를 모두 통합하기는 힘들었습니다.
그러면, 먼저 CRUD 를 처리하기 위해서 Repository 가 가져야 할 필수 메서드들을 선정해 인터페이스를 작성합시다. 우리는 Spring Data JPA 의 상속 구조와 비슷하게 패키지를 작성하겠습니다.
그리고 아래의 abstractmethod 들을 정의하겠습니다. Python 에서는 ABC 모듈을 통해서 추상 메서드를 작성할 수 있죠.
class CRUDRepositoryABC(BaseRepository, ABC, Generic[T]):
"""The Base CRUD Repository class."""
@abstractmethod
def save(self, entity: T) -> T:
"""
Save the given entity.
:param entity: Entity to save.
:return: saved Entity
"""
pass
@abstractmethod
def save_all(self, entities: List[T]) -> List[T]:
"""
Save all given entities.
:param entities: Entities to save.
:return: saved Entities.
"""
pass
@abstractmethod
def read_by_id(self, id: int) -> Optional[T]:
"""
Read the entity with given id.
:return: if entity is found with given id, return it, else return None
"""
pass
@abstractmethod
def is_exists_by_id(self, id) -> bool:
"""
Check if entity with given id exists.
:return: if entity is found with given id, return True, else return False
"""
pass
@abstractmethod
def read_all(
self,
sorting_request: SortingRequest,
filtering_request: FilteringRequest,
) -> List[Optional[T]]:
"""
Read all entities.
if no entities are found, return empty list.
"""
pass
@abstractmethod
def read_all_by_ids(self, ids: List[int]) -> List[Optional[T]]:
"""
Read all entities with given ids.
:return: list of all entities, with given ids.
"""
pass
@abstractmethod
def count(self) -> int:
"""Count all entities."""
pass
@abstractmethod
def delete_by_id(self, id: int) -> None:
"""Delete the entity with given id."""
pass
@abstractmethod
def delete(self, entity) -> None:
"""Delete the given entity."""
pass
@abstractmethod
def delete_all_by_ids(self, ids: List[int]) -> None:
"""Delete all entities with given ids."""
pass
@abstractmethod
def delete_all(self) -> None:
"""Delete all entities, managed by this repository."""
pass
이렇게 추상 클래스를 작성하면, 위의 추상 클래스를 상속받는 모든 클래스들은 @abstractmethod 데코레이터가 붙은 모든 메서드들을 필히 구현해야 합니다.
SQLAlchemy 전용 Repository 구현하기
“Repository 라면, 이것들 정도는 구현해 줘야지!” 를 파이썬 코드로 작성했으니, 우리가 원하던 sqlalchemy 전용 repotsitory 를 구현해 봅시다.
class SQLAlchemyFullRepository(CRUDRepositoryABC, ABC, Generic[T]):
"""
The implementation of CRUDRepositoryABC, with SQLAlchemy.
this implementation has dependency with flask-sqlalchemy's SQLAlchemy object.
"""
def __init__(self, db: SQLAlchemy):
self.db = db
self._model = self.get_model()
@abstractmethod
def get_model(self):
pass
def save(self, entity: T) -> T:
self.db.session.add(entity)
self.db.session.commit()
self.db.session.refresh(entity)
return entity
def save_all(self, entities: List[T]) -> List[T]:
saved_entities = []
for entity in entities:
saved_entity = self.save(entity)
saved_entities.append(saved_entity)
return saved_entities
def read_by_id(self, id: int) -> Optional[T]:
query_result = self.db.session.get(self._model, id)
return query_result if query_result else None
def is_exists_by_id(self, id) -> bool:
return bool(self.db.session.get(self._model, id))
def read_all(
self,
pagination_request: Optional[PaginationRequest] = None,
sorting_request: Optional[SortingRequest] = None,
filtering_request: Optional[FilteringRequest] = None,
) -> Union[List[Optional[T]] | PaginationResponse[T]]:
query = self._get_base_query()
if filtering_request:
query = self._filtering(query=query, filtering_request=filtering_request)
if sorting_request:
query = self._sorting(query=query, sorting_request=sorting_request)
if pagination_request:
query = query.paginate(
page=pagination_request.page,
per_page=pagination_request.per_page,
error_out=False,
)
return PaginationResponse(
count=query.total,
next_page=query.next_num,
previous_page=query.prev_num,
results=[item for item in query.items],
)
else:
return [
query_result
for query_result in self.db.session.execute(select(self._model))
.scalars()
.all()
]
def read_all_by_ids(self, ids: List[int]) -> List[Optional[T]]:
return [self.read_by_id(_id) for _id in ids]
def count(self) -> int:
return self.db.session.query(self._model).count()
def delete_by_id(self, id: int) -> None:
model_instance = self.db.session.get(self._model, id)
if model_instance:
self.db.session.delete(self.db.session.get(self._model, id))
self.db.session.commit()
else:
raise ValueError(f"{self._model} with id {id} not found.")
def delete(self, entity) -> None:
model_instance = self.db.session.get(self._model, entity.id)
if not model_instance:
raise ValueError(
f"{self._model} with entity {entity} not found.\n"
f"make sure the entity instance is stored in database."
)
self.db.session.delete(model_instance)
self.db.session.commit()
def delete_all_by_ids(self, ids: List[int]) -> None:
self.db.session.query(self._model).filter(self._model.id.in_(ids)).delete()
def delete_all(self) -> None:
self._model.query.delete()
def _get_base_query(self) -> Query:
return self.db.session.query(self._model)
def _filtering(self, query: Query, filtering_request: FilteringRequest) -> Query:
"""
filter the query with filtering_object.
this is implementation of `or` condition.
"""
for field, word in vars(filtering_request).items():
query = query.filter(getattr(self._model, field).ilike(f"%{word}%"))
return query
def _sorting(self, query: Query, sorting_request: SortingRequest) -> Query:
for field, direction in vars(sorting_request).items():
if direction == "asc":
query = query.order_by(getattr(self._model, field).asc())
elif direction == "desc":
query = query.order_by(getattr(self._model, field).desc())
return query
대략적으로 위와 같이 구현할 수 있습니다. 아직 개발 중인 프로젝트이기 때문에 최적화 등 상세 구현은 달라질 수 있지만, 위의 구현들이 모두 제대로 동작한다면 어떤 sqlalchemy 모델을 가져오든 단순한 CRUD 정도는 빠르게 처리할 수 있을 것입니다.
Step 03. Transaction 처리하기
지금 코드의 문제: 롤백을 어떻게 처리할 건데?
위의 구현을 사용하면 이제 자유로이 데이터베이스와의 소통을 처리할 수 있을 것만 같아 보입니다. 그리고 실제로 간단한 CRUD 작업과 같은 경우 대부분의 문제 없이 처리할 수 있습니다.
그런데 말이죠, 우리는 몇 가지 간과한 것이 있습니다. 바로 트랜잭션 처리입니다.
def save(self, entity: T) -> T:
self.db.session.add(entity)
self.db.session.commit()
self.db.session.refresh(entity)
return entity우리의 save() 메서드는 들어온 엔티티를 바로 저장하고 커밋해 버립니다. 그렇다면 Service Layer 에서 묶여 처리해야 하는 부분은 되돌릴 수 없음을 의미합니다. “스터디 관련 API” 를 개발한다고 가정해 볼까요?? 누군가 “스터디 참가 신청” 을 하고, “스터디장이 참가 승인” 을 한다면 “승인된 신청 테이블의 `승인 상태`컬럼은 True로 바뀌어야 하고, 스터디의 멤버는 하나가 증가해야” 합니다. 스터디 참가 신청은 완료되어 True가 되었는데, 스터디 멤버가 증가하지 않는다면 안 되겠죠. 비록 데모 코드이지만, 아래의 스터디_서비스() 함수는 수행 시 무조건 다 성공하거나 다 실패해야 합니다.
def 스터디_서비스()
참가신청.approval_status = True
멤버_추가하기(새_멤버)
하지만 위의 리포지토리 구현은 그것을 불가능하게 만듭니다. 그 이유는 리포지토리 내에서 바로 commit() 을 수행하기 때문입니다. 바로 커빗을 진행해 버리니 롤백을 진행할 수 있는 방법이 없습니다. 이는 분명히 나쁜 상태입니다.
db.session.commit() 은 언제 호출해야 하는가? feat. Spring Framework
아마 Spring 프레임워크에 익숙하신 분들은 코드 한 줄이 떠오르셨을지도 모르겠습니다.
@Transactional위에서 간단한 예제를 제시했지만 저는 Spring 프레임워크에 익숙한 사람이 아닙니다. 하지만 위의 어노테이션이 어떻게 사용되는지는 대략적으로 알고 있습니다.
@Transactional
public class SomeService {
//...
}해당 어노테이션은 위의 SomeService 에 대한 트랜잭션 처리를 하겠다는 것을 Spring 에게 알려주는 역할을 합니다. 사실 너무나 많은 내용이 생략되었지만, 아무튼 Spring 에서는 “일련의 작업들을 묶는 것” 을 위와 같이 처리합니다.
그러면, 위의 사용 사례와 비슷한 구현을 시작해봅시다.
우리도 make_transaction 이라는 데코레이터를 정의하여, 서비스 레벨에서 트랜잭션을 명시해줄 수 있는 수단을 제공합시다.
우리가 정의할 데코레이터는 대략 아래와 같이 쓰일 겁니다.
@make_transaction(isolation_level= # ...)
class MyService:
def get_foo():
my_repository.save(foo)
another_repository.save(bar)위의 MyService 클래스에 @make_transaction 이라는 데코레이터를 정의함으로서, get_foo 라는 메서드가 all or nothing 을 보장하도록 만들어주는 겁니다. 해당 데코레이터에 트랜잭션 격리 수준 등을 전해줄 수 있는 인자도 추가합시다.
지금부터는 제가 이것을 어떻게 구현했는지, 실제 작업의 흐름을 따라가보겠습니다.
우리만의 make_transaction 데코레이터 만들기
먼저 테스트 코드를 작성합시다.
def test_transaction_rollback(test_app, user_repository):
"""
Tests that the make_transaction method handles the transaction correctly.
If an error occurs in the wrapped method, the session should be rolled back.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
with pytest.raises(Exception):
def raise_exception():
return 1 / 0
@make_transaction
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
raise_exception()
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 0
def test_transaction_success(test_app, user_repository):
"""
Test that the make_transaction method handles the transaction well.
If the wrapped method doesn't throw any errors, the database should have two users successfully committed.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
@make_transaction
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 2
def test_without_decorator(test_app, user_repository):
"""
Without the make_transaction decorator, no changes will be made to the actual database,
so the user should remain unsaved.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
with pytest.raises(Exception):
def raise_exception():
return 1 / 0
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
raise_exception()
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 0
총 세 가지 테스트 케이스를 가정했습니다. 한번 볼까요?
def test_transaction_rollback(test_app, user_repository):
"""
Tests that the make_transaction method handles the transaction correctly.
If an error occurs in the wrapped method, the session should be rolled back.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
with pytest.raises(Exception):
def raise_exception():
return 1 / 0
@make_transaction
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
raise_exception()
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 0먼저, 첫 번째 테스트 케이스에서는 @make_transaction 을 사용하여 save_user() 메서드에 대한 트랜잭션을 만들었습니다. save_user() 메서드가 호출된다면 필히 ZeroDivisionError 가 발생할 것이므로, 위의 두 줄은 롤백되어야 하죠. 결과적으로 데이터베이스에는 아무런 사용자도 저장되면 안 됩니다.
def test_transaction_success(test_app, user_repository):
"""
Test that the make_transaction method handles the transaction well.
If the wrapped method doesn't throw any errors, the database should have two users successfully committed.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
@make_transaction
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 2두 번째 테스트 케이스에서는 save_user 도중 아무런 에러가 발생하지 않으므로 데이터베이스에 커밋이 되어야 합니다. 그렇다면 예상했던 대로 데이터베이스에는 두 명의 사용자가 저장되어야 하겠죠?
def test_without_decorator(test_app, user_repository):
"""
Without the make_transaction decorator, no changes will be made to the actual database,
so the user should remain unsaved.
"""
with test_app.test_request_context():
user_fullask = UserModel(name="mr_fullask")
user_spring = UserModel(name="mr_spring")
with pytest.raises(Exception):
def raise_exception():
return 1 / 0
def save_user():
user_repository.save(user_fullask)
user_repository.save(user_spring)
raise_exception()
save_user()
with test_app.test_request_context():
assert UserModel.query.count() == 0
세 번째 테스트 케이스에서는 @make_transaction 데코레이터를 사용하지 않았으므로, 커밋 자체가 일어나지 않았기 때문에 사용자 두 명이 저장되지 않아야 합니다. 단지 add() 만 수행될 뿐이죠.
def make_transaction(func):
@wraps(func)
def wrapper(*args, **kwargs):
session = current_app.extensions["sqlalchemy"].session
try:
with session.begin_nested():
result = func(*args, **kwargs)
session.commit()
return result
except Exception as e:
session.rollback()
raise e
return wrapper
우리는 위와 같은 데코레이터를 구현할 수 있습니다. 트랜잭션 격리 수준을 정하는 등 원하던 몇 가지 기능이 빠졌지만 말이죠. 함수 시작과 끝에 세션을 시작하고, 함수 수행 후 커밋을 수행합니다. 만약 어떤 에러가 발생한다면, 세션은 롤백될 겁니다.
그러면 실제 sql 은 어떻게 만들어지는지 확인해봅시다!
첫 번째 테스트 케이스에 대해서, sql 은 아래와 같이 만들어집니다.
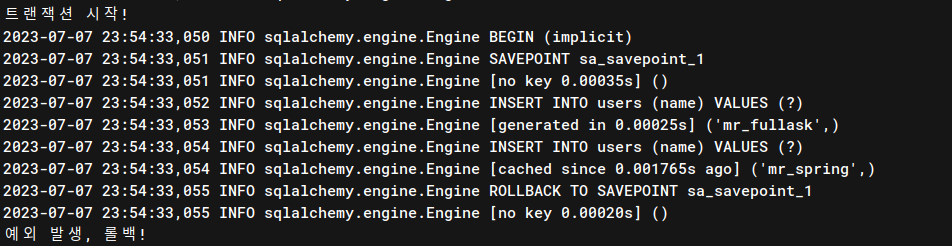
의도했던 대로, mr_fullask, mr_spring 이라는 사용자 두 명을 저장하는 트랜잭션을 만들었지만 save_user() 를 수행하던 도중 예외가 발생했기 때문에 그것을 롤백합니다.
두 번째 테스트 케이스는,
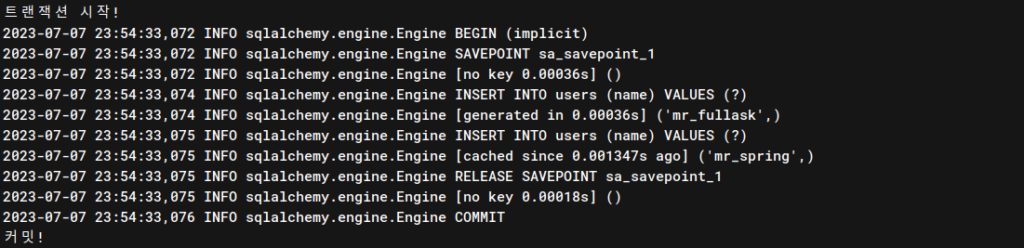
사용자 두 명을 저장하려고 시도했고, 묶여있는 함수 save_user 에 대해서 아무런 예외도 발생하지 않았으므로 커밋을 성공적으로 수행하는 것을 확인할 수 있습니다.

세 번째 테스트 케이스에 대해서는, 애초에 savepoint 자체가 만들어지지 않습니다. repository 의 save() 메서드에서 flush() 만 호출했을 뿐 커밋을 수행하지 않았습니다. 그렇기 때문에 요청이 끝날 때에 자동으로 롤백이 됩니다.
마치며
나름대로 Flask 와 SQLALchemy 를 통해서 트랜잭션을 구현했습니다. 섣불리 repository 내에서 commit() 을 수행하던 것을 옮기는 과정이 괜찮았다는 생각은 듭니다만, 조금 찜찜한 점들도 있습니다.
- 앞으로 리포지토리를 사용할 때에는
make_transaction데코레이터를 무조건 사용해야 합니다. - 각 세션마다 트랜잭션 격리 수준을 설정하지는 못했습니다. 일단은 이대로 두되, 서비스를 개발하며 문제가 생기는 부분이 있다면 수정할 생각입니다.
위의 과정들은 어쩌면 객기라고 불릴 수도 있을 만큼, 그냥 “나름대로” 만들어 본 것이기에 절대 모범 사례가 아닙니다. 아마도 제가 sqlalchemy 의 코어 기능들을 더 잘 알았다면 더 멋진 트랜잭션 데코레이터를 구현했을 수도 있겠죠. 그리고 바라건대 앞으로 그렇게 되었으면 좋겠습니다.
