[Flask] – “인스타그램 클론코딩 – Instagram Clone (2)”
[Flask] – “인스타그램 클론코딩 – Instagram Clone (2)”
오늘 할 것
이전에 작성했던 사용자 모델을 개선하고, 게시물과 댓글 모델을 작성한 다음, 게시물 목록, 상세, 생성, 수정, 삭제 API 를 구현해 보도록 하겠습니다. 간단한 테스트 코드를 이용해서 목록 API를 테스트하는 것도 해 보겠습니다!
User, Post, Comment 모델 작성
먼저, 전에 만들어두었던 마이그레이션 파일과 데이터베이스를 삭제하고 다시 시작하겠습니다. (원래는, 마이그레이션 파일은 건드리지 않습니다..!)
이전에 작성한 사용자 모델을 개선함과 동시에, 다른 여러 가지 모델들도 작성해 보겠습니다. 총 세 가지 모델을 정의할 겁니다.
User 모델의 코드는 아래와 같습니다. (user.py)
from ..db import db
followers = db.Table(
'followers',
# 나를 팔로우하는 사람들의 id
db.Column('follower_id', db.Integer, db.ForeignKey('User.id', ondelete='CASCADE'), primary_key=True),
# 내가 팔로우한 사람들의 id
db.Column('followed_id', db.Integer, db.ForeignKey('User.id', ondelete='CASCADE'), primary_key=True)
)
class UserModel(db.Model):
"""
Flastagram 사용자 모델
username : 사용자 이름, 80자 제한, 중복된 값을 가질 수 없음
password : 사용자 비밀번호, 80자 제한
email : 이메일, 중복된 값을 가질 수 없음
created_at : 사용자가 가입한 날짜
"""
__tablename__ = "User"
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), nullable=False, unique=True)
password = db.Column(db.String(80), nullable=False)
email = db.Column(db.String(80), nullable=False, unique=True)
created_at = db.Column(db.DateTime, server_default=db.func.now())
followed = db.relationship( # 본인이 팔로우한 유저들
'UserModel', # User 모델 스스로를 참조
secondary=followers, # 연관 테이블 이름을 지정
primaryjoin=(followers.c.follower_id==id), # followers 테이블에서 특정 유저를 팔로우하는 유저들을 찾음
secondaryjoin=(followers.c.followed_id==id), # followers 테이블에서 특정 유저가 팔로우한 모든 유저들을 찾음
backref=db.backref('follower_set', lazy='dynamic'), # 역참조 관계 설정
lazy='dynamic'
)
def follow(self, user):
"""
특정 사용자를 팔로우
"""
if not self.is_following(user):
self.followed.append(user)
return self
def unfollow(self, user):
"""
특정 사용자를 언팔로우
"""
if self.is_following(user):
self.followed.remove(user)
return self
def is_following(self, user):
"""
현재 사용자가 특정 사용자를 팔로우하고 있는지에 대한 여부 반환 (True or False)
"""
return self.followed.filter(followers.c.followed_id == user.id).count() > 0
@classmethod
def find_by_username(cls, username):
"""
데이터베이스에서 이름으로 특정 사용자 찾기
"""
return cls.query.filter_by(username=username).first()
@classmethod
def find_by_id(cls, id):
"""
데이터베이스에서 id 로 특정 사용자 찾기
"""
return cls.query.filter_by(id=id).first()
def save_to_db(self):
"""
사용자를 데이터베이스에 저장
"""
db.session.add(self)
db.session.commit()
def delete_from_db(self):
"""
사용자를 데이터베이스에서 삭제
"""
db.session.delete(self)
db.session.commit()
def __repr__(self):
return f'<User Object : {self.username}>'
이전 게시물에서 언급했듯, 팔로우 기능을 구현하기 위해서 매개 테이블을 하나 만들어주었고, 이후 작업에 필요할 메서드들을 몇 가지 정의해 주었습니다.
post.py 에는 게시물에 관한 모델을 정의하겠습니다.
from ..db import db
from sqlalchemy.sql import func
class PostModel(db.Model):
"""
Flastagram 게시물 모델
title : 게시물의 제목, 150자 제한
content : 게시물의 내용, 500자 제한
created_at : 게시물의 생성일자, 기본적으로 현재가 저장
updated_at : 게시물의 생성일자, 게시물이 수정될 때마다 업데이트
author_id : 게시물의 저자 id, 외래 키
comment_set : 게시물에 달린 댓글들
"""
__tablename__ = "Post"
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(150))
content = db.Column(db.String(500))
created_at = db.Column(db.DateTime(timezone=True), default=func.now())
updated_at = db.Column(db.DateTime(timezone=True), default=func.now(), onupdate=func.now())
author_id = db.Column(db.Integer, db.ForeignKey("User.id", ondelete="CASCADE"), nullable=False)
author = db.relationship("UserModel", backref="post_author")
comment_set = db.relationship("CommentModel", backref="post", passive_deletes=True)
@classmethod
def find_by_id(cls, id):
"""
데이터베이스에서 id 로 특정 게시물 찾기
"""
return cls.query.filter_by(id=id).first()
@classmethod
def find_all(cls):
return cls.query.all()
def save_to_db(self):
"""
게시물을 데이터베이스에 저장
"""
db.session.add(self)
db.session.commit()
def delete_from_db(self):
"""
게시물을 데이터베이스에서 삭제
"""
db.session.delete(self)
db.session.commit()
def __repr__(self):
return f"<Post Object : {self.title}>"
comment.py 에는 댓글 모델을 정의하겠습니다.
from ..db import db
from sqlalchemy.sql import func
class CommentModel(db.Model):
"""
Flastagram 댓글 모델
content : 댓글의 내용
created_at : 댓글의 생성일자
updated_at : 댓글의 수정일자
author_id : 해당 댓글의 저자 id
post_id : 해당 댓글의 게시물 id
"""
__tablename__ = "Comment"
id = db.Column(db.Integer, primary_key=True)
content = db.Column(db.Text(), nullable=False)
created_at = db.Column(db.DateTime(timezone=True), default=func.now())
updated_at = db.Column(db.DateTime(timezone=True), onupdate=func.now())
author_id = db.Column(db.Integer, db.ForeignKey('User.id', ondelete='CASCADE'), nullable=False)
author = db.relationship("UserModel", backref="comment_author")
post_id = db.Column(db.Integer, db.ForeignKey('Post.id', ondelete='CASCADE'), nullable=False)
def save_to_db(self):
"""
댓글을 데이터베이스에 저장
"""
db.session.add(self)
db.session.commit()
def delete_from_db(self):
"""
댓글을 데이터베이스에서 삭제
"""
db.session.delete(self)
db.session.commit()
@classmethod
def find_by_id(cls, id):
"""
데이터베이스에서 id 로 특정 댓글 찾기
"""
return cls.query.filter_by(id=id).first()
def __repr__(self):
return f'<Comment Object : {self.content}>'
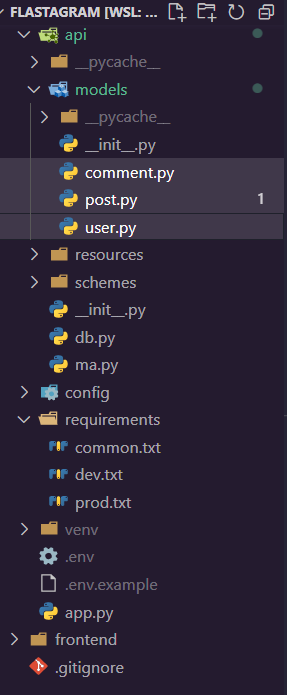
위의 작업을 완료하였다면, api/__init__.py 에 우리가 만든 모델을 등록해 주겠습니다.
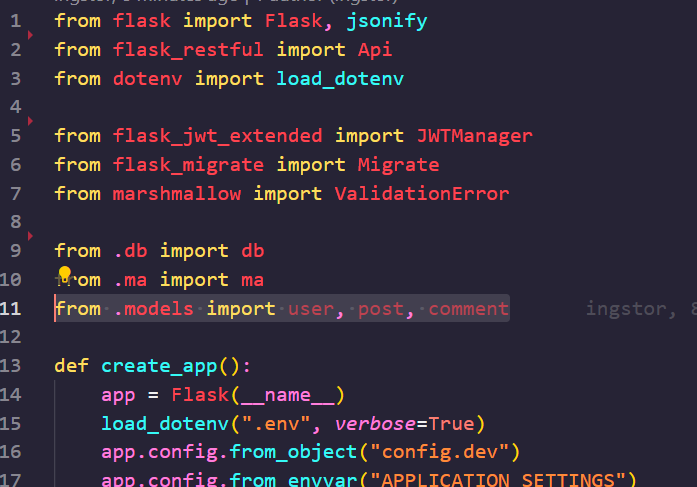
이후, 우리는 플라스타그램 데이터베이스와 마이그레이션 파일들을 모두 삭제했으므로.. 터미널의 위치가 backend/ 인지 확인한 후, flask db init 을 입력해 줍니다.
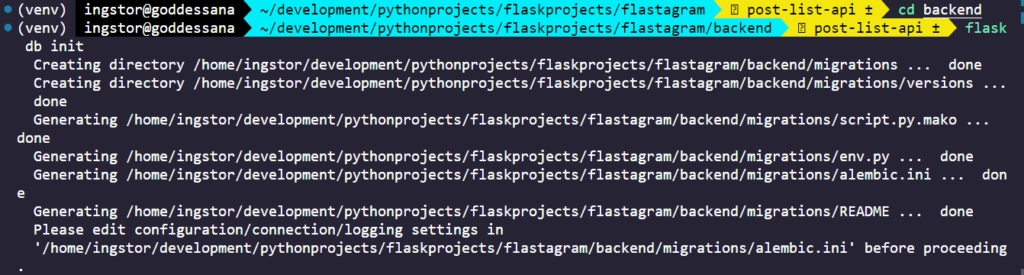
이후로는, 모델의 마이그레이션 파일을 생성해야 하므로 flask db migrate 을 입력해 줍니다.
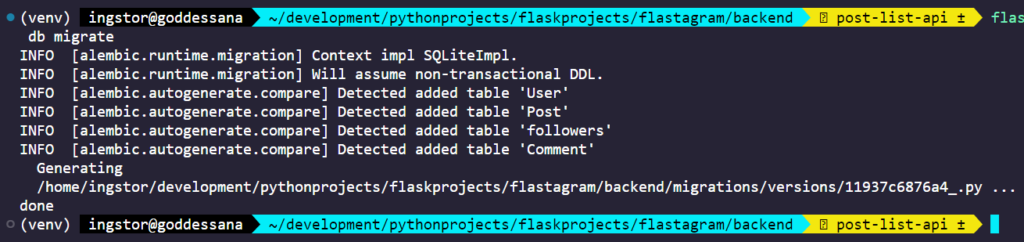
여러 가지 테이블들을 찾아냈고, 그에 대한 마이그레이션 파일을 생성했습니다. 이제, 이를 실제로 데이터베이스에 적용하기 위해서 flask db upgrade 를 수행합니다.

그러면, 데이터베이스에 해당 테이블들이 생성된 것을 확인할 수 있을 겁니다.
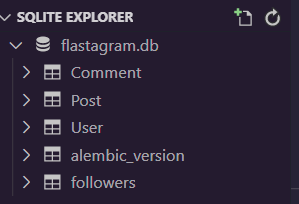
이제, 우리의 모델들을 활용해서 게시물 API를 구현해 보겠습니다!
글목록 API 구현하기
우리는 데이터베이스를 파이썬의 클래스로 다루고 있습니다. 클래스를 작성하고, migrate, upgrade 를 수행하면 실제로 데이터베이스에 우리가 작성한 테이블들이 생성되는 것을 확인할 수 있었습니다.
이러한 클래스들을 JSON 으로 다루기 위해서 marshmallow 라이브러리에 대해서 알아봤던 것을 기억하시나요? 해당 라이브러리를 사용하면, 들어오는 데이터에 대한 검증을 쉽게 할 수 있고, 직렬화/역직렬화를 쉽게 할 수 있다는 장점이 있었습니다.
작업을 시작하기 전, 게시물 목록 api를 호출한다면, 게시물 하나에 대한 응답으로 어떤 형태의 json 이 들어와야 할 지 생각해 보겠습니다. 기본적으로 게시물의 id, 게시물의 생성일자, 게시물의 수정일자, 저자의 이름, 제목, 내용이 응답으로 들어와야 한다고 가정하겠습니다. 아래의 형태가 되겠죠?

그런데, 현재의 Post 모델은 맨 처음에 게시물을 저장할 때에, updated_at 이 null로 저장됩니다. 이 부분을 해결해 보겠습니다. 이것을 수행하는 목적은, “게시물을 생성할 때에 created_at 과 updated_at 에 같은 값이 저장되도록 하고, 게시물이 수정된다면 updated_at 의 값만 갱신되도록 하는 것” 입니다.
PostModel 클래스에 아래의 코드를 수정해 주세요. default=func.now() 를 넣어주면 됩니다.

첫째, 플라스크의 Pluggable View 와 Schema 에 대해서 어느 정도 개념이 있다면, 아래의 아이디어를 떠올릴 수 있습니다.
- Schema 를 통해서 Post 모델 객체를 직렬화한다.
- Resource 에 추가한다.
- 추가한 Resource를 app에 등록한다.
위의 작업들이 필요할 겁니다. 최종적으로, 구현하고자 하는 API의 형태는 아래와 같습니다.
| HTTP Method | URL | 역할 |
|---|---|---|
| GET | posts/ | 게시물의 목록을 조회 |
| POST | posts/ | 새로운 게시물을 하나 생성 |
| GET | posts/<id> | 특정 게시물을 하나 조회 |
| PUT | posts/<id> | 특정 게시물이 존재한다면 수정, 존재하지 않는다면 삭제 |
| DELETE | posts/<id> | 특정 게시물을 하나 삭제 |
둘째, 이제 작업을 시작해 볼까요? 게시물 목록을 조회하는 API를 구축할 것이므로, 우리는 모델 클래스를 직렬화한 후 응답으로 보내주어야 합니다.
schemas/ 아래에 __init__.py, post.py 를 만들어 주겠습니다.
이후, ma.py 에 아래와 같은 코드를 작성해 줍니다. Method는 나중에 사용할 것인데, 일단 넘어가겠습니다!
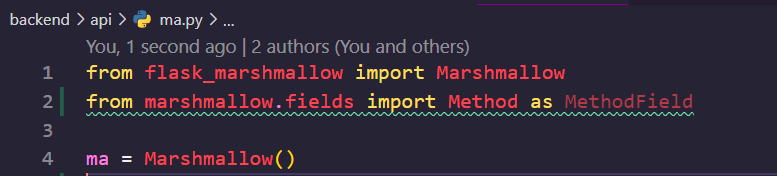
그리고 스키마를 작성해 줍니다.
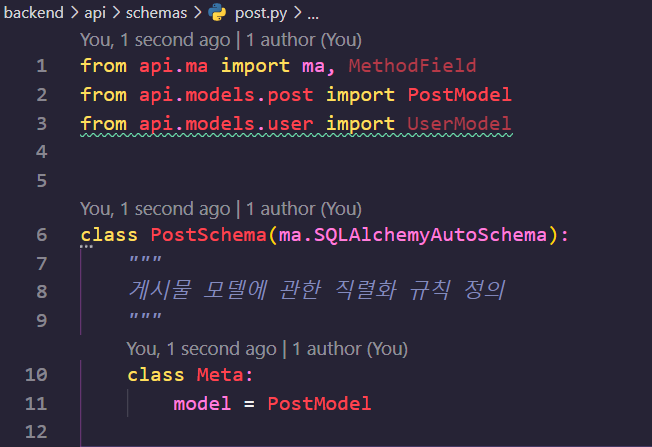
기본적으로 SQLALChemyAutoSchema 를 상속받아 작성되었고, 메타 클래스에는 “이 모델을 직렬화하고 싶어!” 를 명시해 주었네요.
이후, 이제는 Resources 를 작성하겠습니다. 아래와 같은 파일들을 작성해 주세요! (__pychache__ 제외)
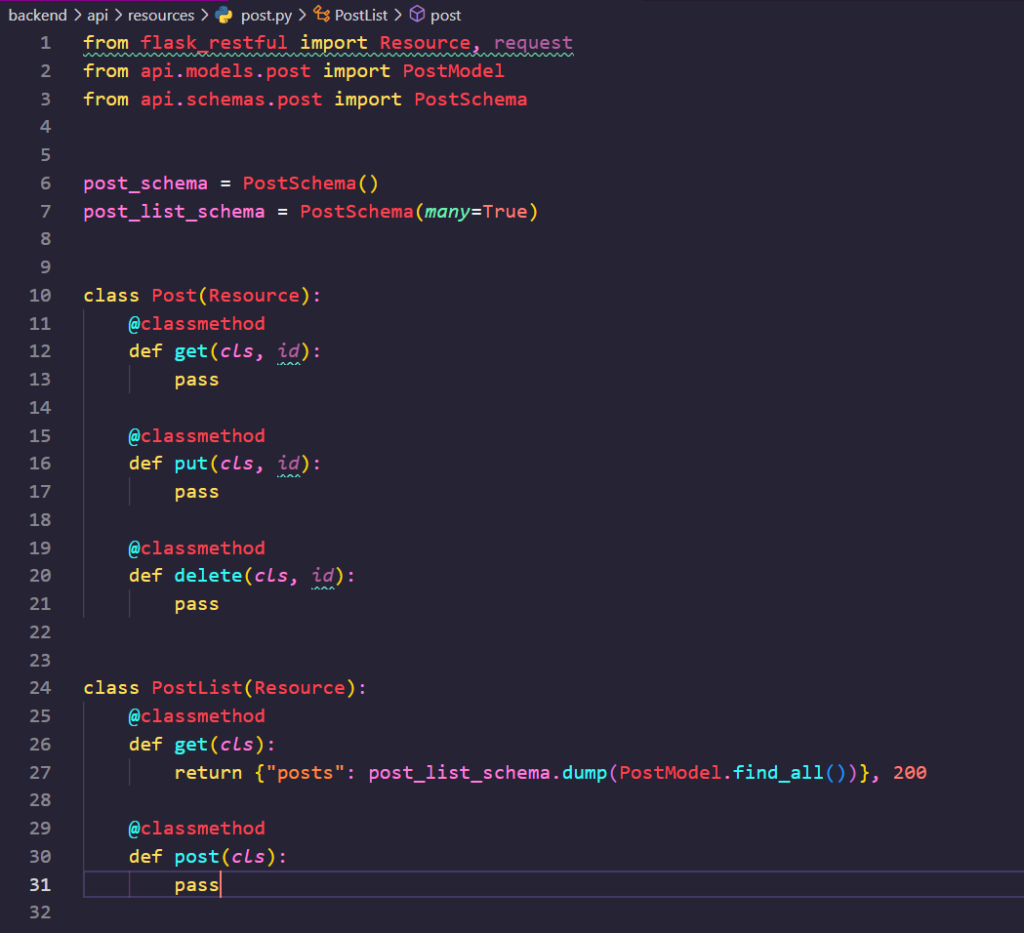
6번 줄과 7번 줄에서 각각 게시물 상세에 대한 스키마, 게시물 목록에 관한 스키마를 정의해 주었습니다. many=True 옵션을 준 것인데, 마시멜로 공식 문서에는 아래와 같이 소개되어 있네요!

users 를 직렬화하기 위해서 many=True 를 설정한 후 직렬화한 것을 볼 수 있습니다.
아무튼, 24~27 번 줄에서는 “게시물 목록에 관한 GET 요청이 들어왔을 때 어떻게 그것을 처리할 것인가?” 를 정해주고 있습니다. Pluggable View를 알고 있다면 쉽게 이해할 수 있을 겁니다. 단순히 get() 메서드를 재정의함으로서, 클라이언트가 GET 요청을 보냈을 때에 어떻게 처리할 것인지를 정의해 줄 수 있었죠?

위의 코드를 보고 응답이 어떻게 올지를 상상해 보세요. 어떠한 형태로 응답이 오겠구나가 약간 상상이 되시나요?
post_list_schema 는 PostModel.find_all() 을 변환해 주고 있습니다. find_all() 은 우리가 모델 단에서 작성했던 함수죠?
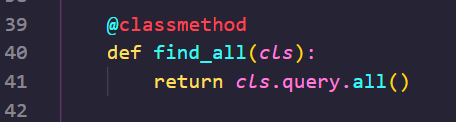
이는 현재 클래스(PostModel).query.all() 을 반환해 줄 겁니다. 그리고, 이를 post_list.schema.dump() 를 사용해 직렬화해 줬습니다.
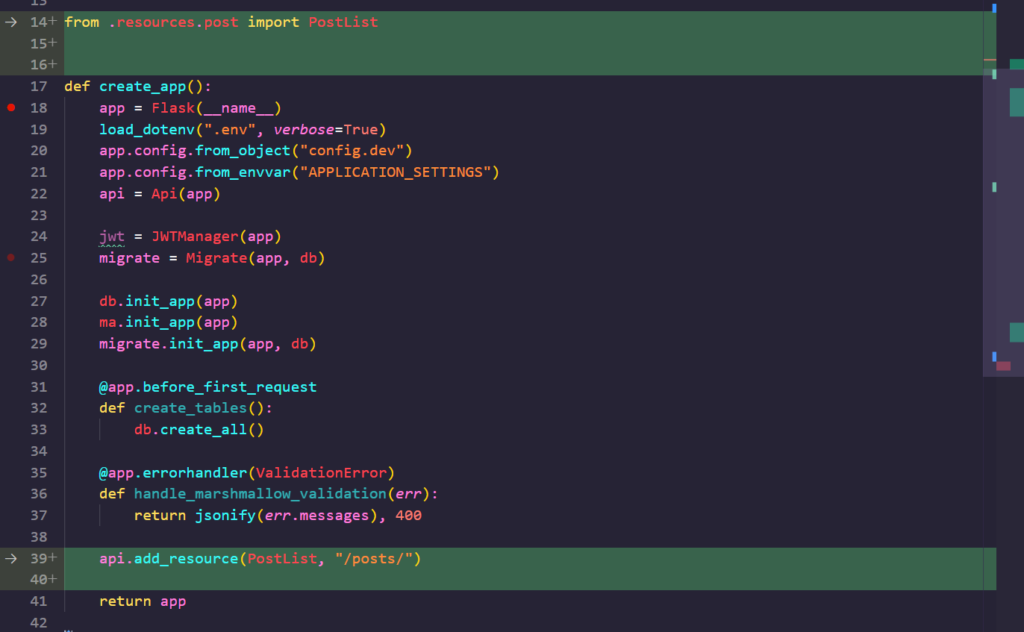
그러면, __init__.py 에 위의 코드를 추가해서 리소스를 등록해 줍니다. 그리고 서버를 실행한 다음, /posts/ 로 이동해 보세요.
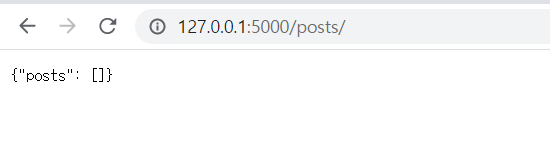
현재 데이터베이스에 게시물이 존재하지 않으므로 posts에 아무런 것도 나오지 않았네요. 실제 게시물을 추가하고, 응답이 제대로 나오나 확인해 보겠습니다!
그런데, 게시물을 생성하기 위해서는 게시물의 작성자가 필요합니다. 데이터베이스에서 새로 유저 한 명을 생성해 주세요. 저는, flask shell 을 사용해서 아래와 같이 새 유저를 만들겠습니다.
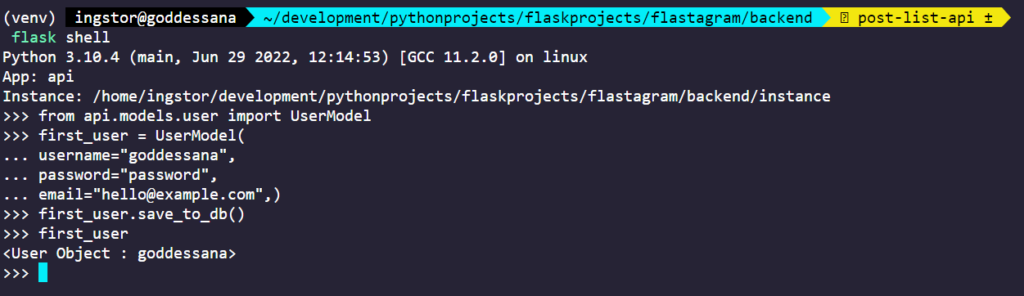
모델 단에서 만들어 두었던 save_to_db() 메서드를 사용하여 만들 수 있습니다.
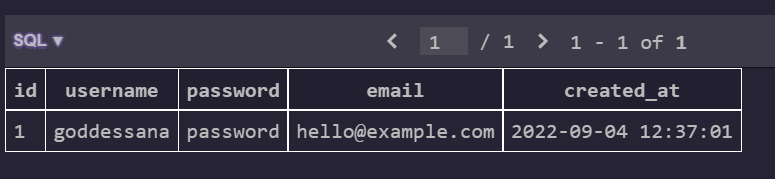
테이블에 잘 저장된 것을 볼 수 있네요!
그리고, 이제는 게시물을 두 개 정도 만들겠습니다. flask shell을 이용해서 아래와 같이 만들었습니다.
간단하게 포스트 모델 클래스를 불러오고, 해당 클래스의 인스턴스를 만들고, 그것의 save_to_db() 메서드를 사용해서 데이터베이스에 저장했습니다.


아래와 같이, 테이블에 게시물 정보들이 잘 저장되었습니다.

그리고, 다시 /posts/ 에 접속해 봅시다.
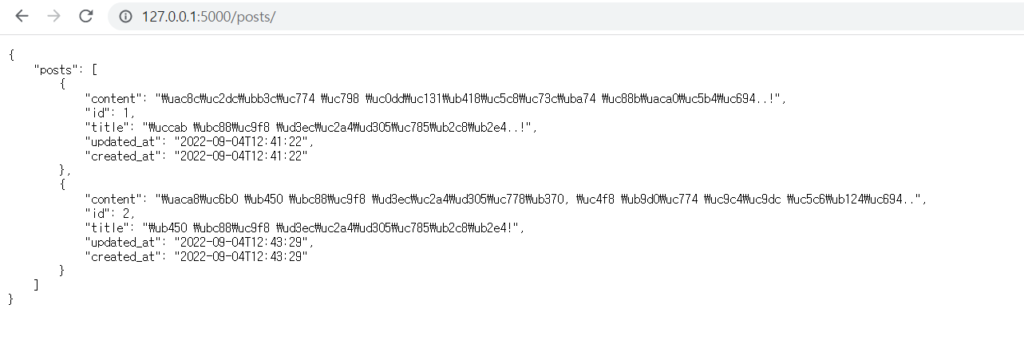
WOW! 우리가 작성한 게시물의 목록 API가 잘 나타나네요.
그런데, 한글이 깨지고 있네요. 아래의 코드를 create_app() 에 작성하여 해결해 줍니다.
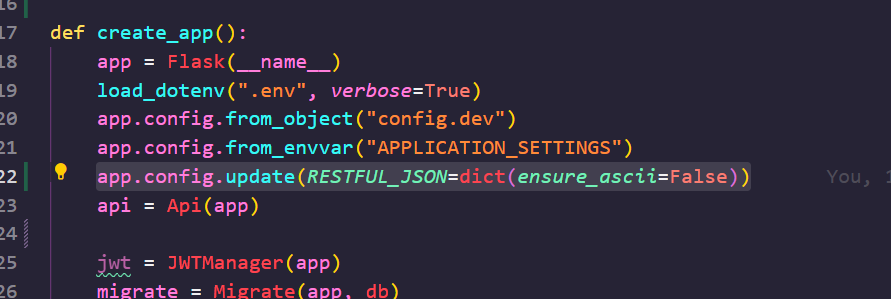
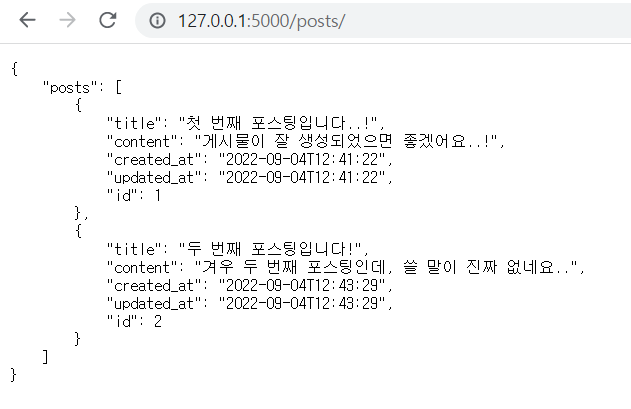
글 생성 API 구현
좋아요, 위의 화면을 보면 글 목록에 대한 API는 제대로 동작하고 있는 것처럼 보입니다. 하지만 몇 가지 고칠 점이 있습니다. 첫째로는, 게시물 목록 API에는 저자의 id 가 아닌 저자의 이름 자체가 들어갔으면 좋겠네요. 둘째로는, 게시물을 입력할 때에는 “저자 id” 를 입력하지 않아도, 게시물이 저장되었으면 좋겠네요.
이게 무슨 말이냐..
먼저, 인스타그램에서 새 피드를 올릴 때를 상상해 봅시다. 사진을 선택하고, 사진에 걸맞는 멋진 명언을 하나 작성하고 나서 “게시하기” 버튼을 누르죠. 그러면, 작성자는 본인의 계정으로, 선택한 사진과 함께 멋진 명언이 피드로서 게시됩니다.
그런데, 생각해 보면 우리는 게시물을 작성할 때에 “저자 id” 와 같은 부분을 입력하지 않았습니다. 단지 로그인한 후, 게시물을 추가했을 뿐인데 “이 게시물은 현재 로그인한 유저가 썼어!” 를 처리해 주었죠.
그런데, 우리가 작성한 스키마를 잠시 살펴볼까요? 우리의 스키마는 SQLAlchemyAutoSchema 를 상속받아 만들어졌습니다.

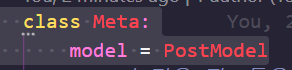
그것은 우리의 모델을 딕셔너리로 처리하는 작업을 적당히 해 줄 겁니다. 예컨대 “생성일자”, “수정일자” 는 데이터베이스에 저장될 때에 시간이 자동으로 저장되도록 했으므로 입력할 필요가 없죠. 실제로 실습을 해 보겠습니다.
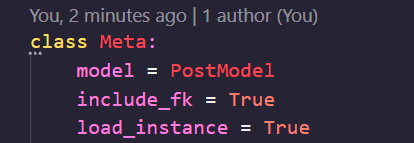
게시물 생성을 위해서 포스트 스키마를 위와 같이 조금 수정하겠습니다. 모델은 게시물 모델을 가리키고 있는 것은 같고,
include_fk 는 외래 키 포함 여부를,
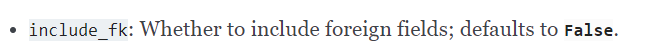
load_instance 는 모델 객체를 로드할지에 대한 여부를 나타냅니다.

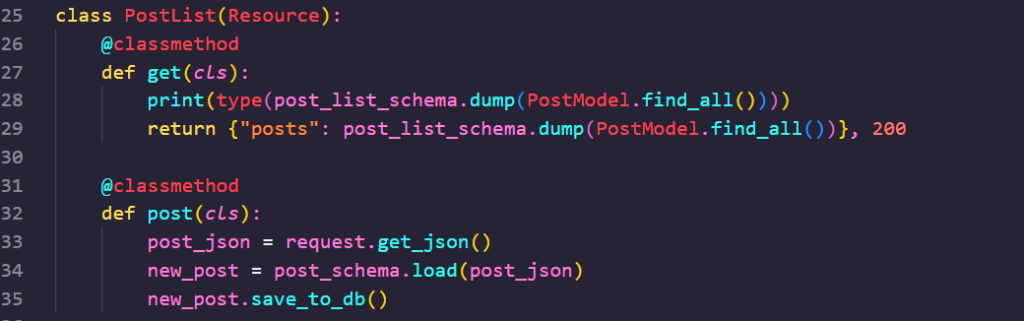
그리고 위와 같이 post 메서드를 작성해 보겠습니다. get_json() 으로 우리가 보낸 json 데이터를 얻어온 다음, post_schema.load() 를 통해 그것을 게시물 인스턴스로 변환한 다음, 그것을 save_to_db() 메서드를 사용해서 데이터베이스에 저장할 겁니다.
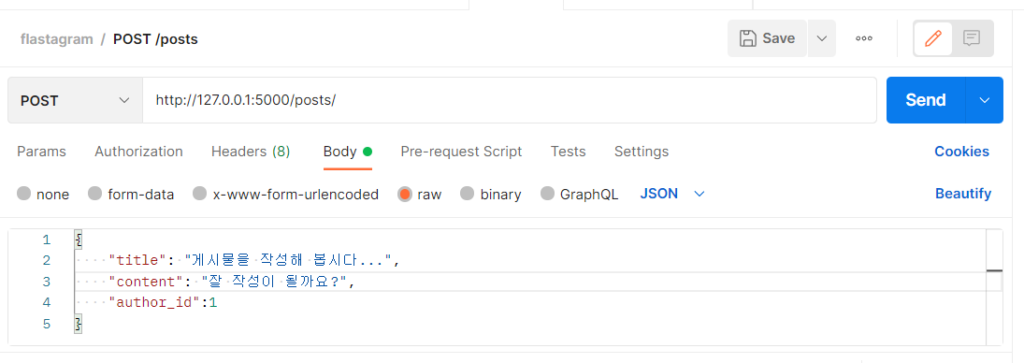
그리고 POSTMAN 을 사용해서 위와 같은 json 데이터를, /posts/ 에 POST 요청과 함께 보내 보세요. 아직 post() 메서드에서 리턴값이 없으므로 null이 뜰 겁니다.
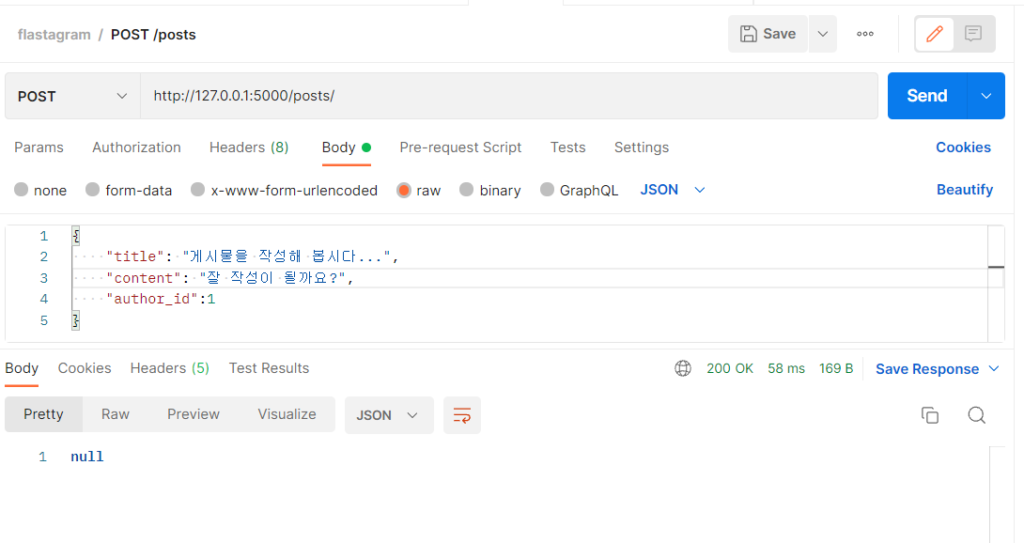
데이터베이스에 값이 잘 추가되었는지 확인해 볼까요?

놀랍게도(?) 저장이 잘 된 것을 확인할 수 있습니다. 저자 id도 우리가 쓴 그대로 저장이 잘 되었네요.
이쯤에서 우리가 개선해야 할 두 가지 부분을 다시 읊어 볼까요?
첫째로는, 게시물 목록 API에는 저자의 id 가 아닌 저자의 이름 자체가 들어갔으면 좋겠네요. 둘째로는, 게시물을 입력할 때에는 “저자 id” 를 입력하지 않아도, 게시물이 저장되었으면 좋겠네요.
핵심은 같은 “저자” 를 다루지만 글을 작성할 때에는 id 값을 직접 입력하지 않아야 하고, 글에 대한 정보를 확인할 때에는 저자의 닉네임이 보여야 한다는 겁니다. 예를 들면, 우리가 요청을 보낼 때에는 아래와 같이 보내도 “게시물의 저자는 이 사람이야!” 가 처리되어야 합니다. 현재는 이 필드가 필수 필드이므로, 요청이 처리되지 않을 겁니다.
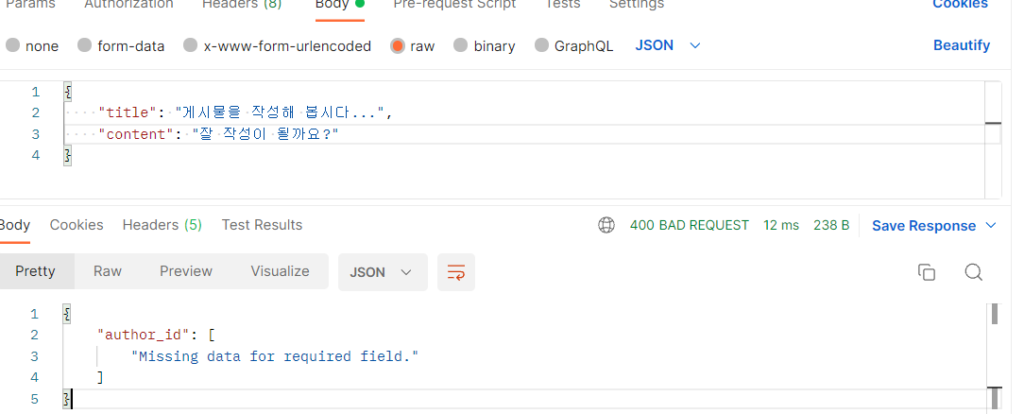
그리고, 우리가 원하는 요청은 아래와 같이 와야 합니다.

author_name 이 새로 생기고, author_id 는 없어진 것을 볼 수 있죠? 이 부분을 처리해 보겠습니다.
현재 로그인은 구현되지 않았으므로, “로그인한 유저를 게시물의 저자로 자동 추가한다” 는 일단 구현할 수 없겠네요. 그렇다면, 일단 “author_name” 을 추가해 보겠습니다. 무미건조한 저자의 외래 키 id 대신, 저자의 닉네임을 가져와야 합니다.
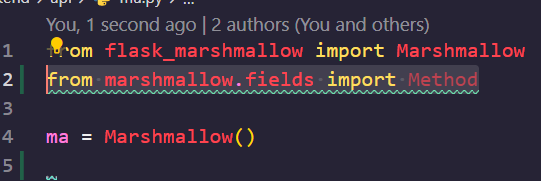
먼저, Method 를 사용할 것이므로 ma.py 에서 위의 줄을 추가해 주세요.
그리고, schemas/post.py 에 아래의 임포트를 추가해 줍니다.
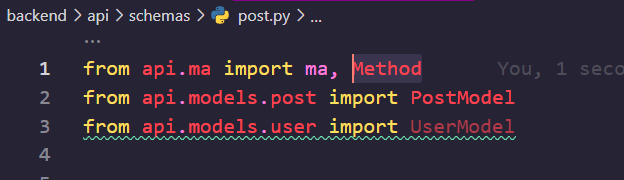
그리고, 아래와 같이 스키마를 조금 수정합니다.

“author_name” 이라는 메소드 필드를 하나 추가하고, get_author_name 이라는 메서드를 하나 정의해서 해당 필드에 obj의 저자의 이름이 나오도록 하였습니다. 그리고, author_id 는 보여주지 않고 쓰기만 할 것이므로 load_only 필드에 넣어주었습니다.
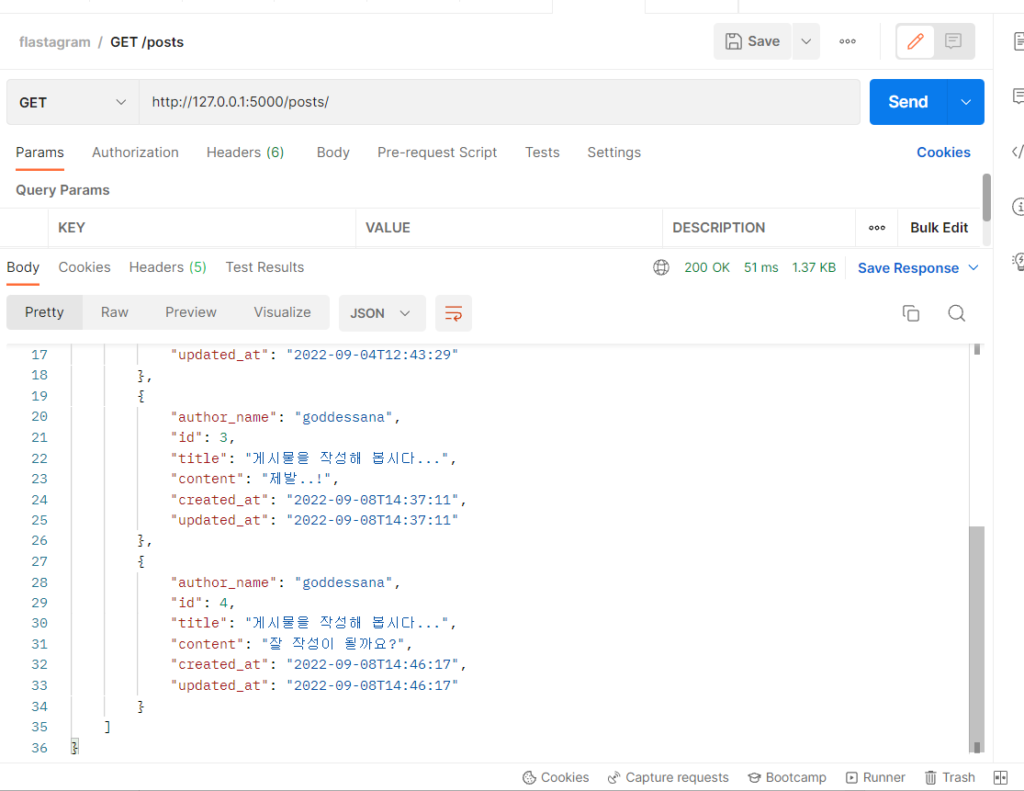
그리고 요청을 보내 보세요. 위와 같이 author_name 이 잘 표시될 겁니다. Post List 에 대한 전체 코드는 아래와 같겠네요.
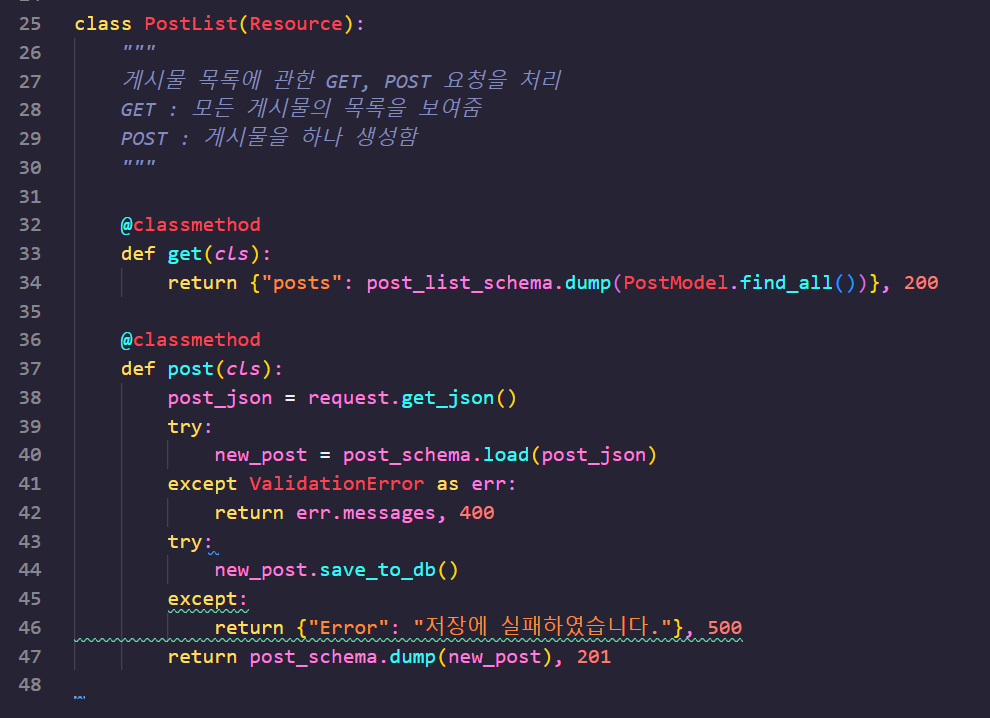
post 메서드에 두 가지의 예외 처리가 적용되었습니다. 검증이 실패할 시 클라이언트에서 잘못된 요청을 보냈다는 400 상태 코드와 함께 에러 메시지를, 어떠한 이유로 데이터베이스에 저장을 실패할 시 500 상태 코드와 에러 메시지를 반환하도록 하였습니다.
좋아요, 우리는 아래와 같은 구조의 API 를 구현하였습니다.
| METHOD , URL | 역할 |
|---|---|
| GET /posts | 모든 게시물의 목록 조회 |
| POST /posts | 게시물을 하나 생성 |
그리고, 아래와 같은 API 를 추가로 구현하겠습니다.
| METHOD, URL | 역할 |
|---|---|
| GET /posts/<id> | <id> 로 구별되는 특정한 게시물을 하나 조회 |
| PUT /posts/<id> | <id> 로 구별되는 특정한 게시물의 정보를 수정, 만약 <id>로 구별되는 특정한 게시물이 없다면 하나 생성 |
| DELETE /posts/<id> | <id> 로 구별되는 특정한 게시물 하나를 삭제 |
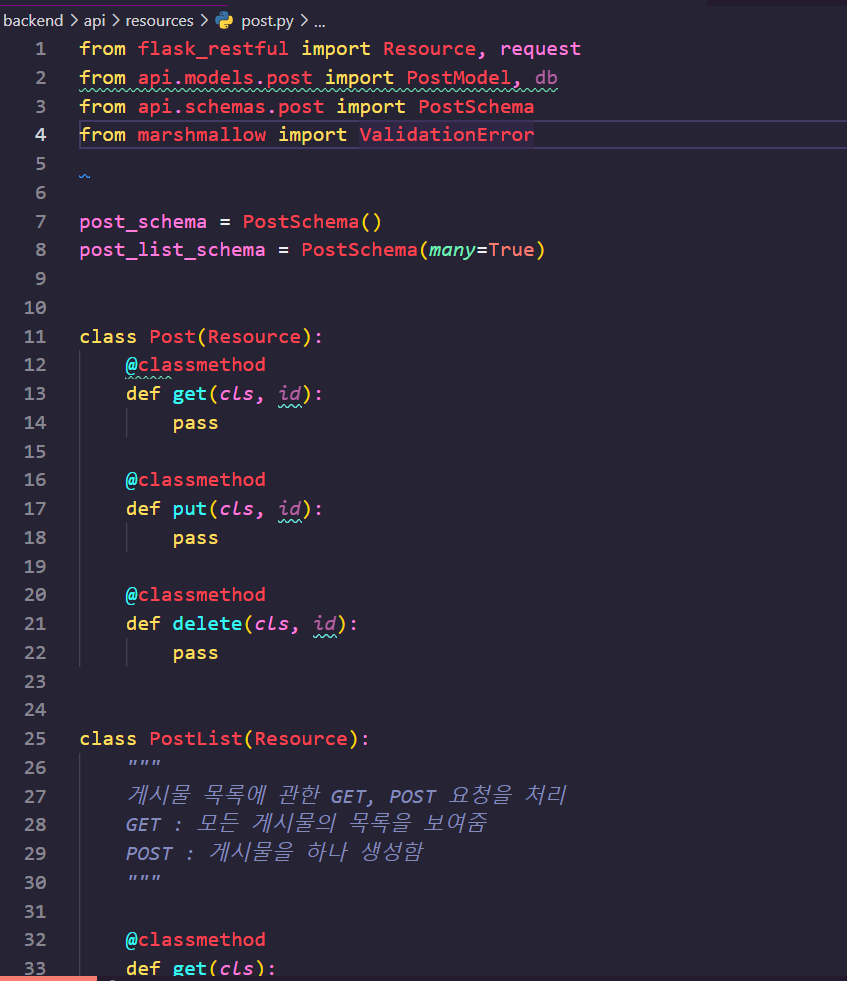
Post 리소스를 하나 정의함으로서 시작해 보겠습니다.
먼저 get 메서드는 손쉽게 구현할 수 있습니다.

게시물을 id로 찾은 다음, 만약 없는 게시물이라면 게시물이 없다는 404 상태 코드와 함께 에러 메시지를 돌려주면 됩니다.
delete 또한 아래와 같이 구현할 수 있겠죠?

게시물을 url의 id 로 찾은 다음, 그것이 존재한다면 삭제를, 그렇지 않다면 불평을 내뿜어 주면 됩니다.
put의 경우, 약간 복잡합니다.
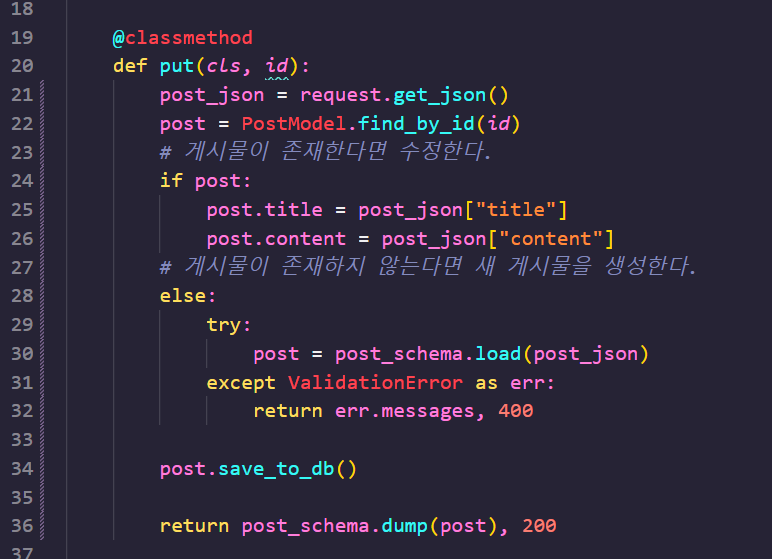
id로 특정되는 게시물이 존재하지 않는다면 새 게시물을 생성하고, id로 특정는 게시물이 없다면 새로운 게시물을 만들어낼 겁니다.
만들어준 리소스를 아래와 같이 등록합니다.
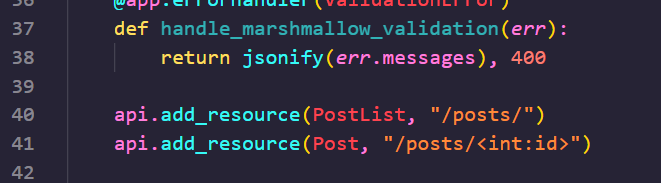
이렇게 posts/ 에 대한 CRUD 를 모두 구현해 보았습니다. 간단하게 테스트를 해 볼까요?
테스트 코드 작성하기
싫어할 거 압니다. 그런데 생각해 보면 포스트맨과 같은 도구로 테스트하는 것보다, 테스트 코드 잘 짜 두고 돌리는 게 훨씬 빨라용..
일단, 테스트를 위해서 데이터베이스를 다시 구성해야 합니다. .env 파일을 기억하시나요? 4번 줄을 추가합니다.
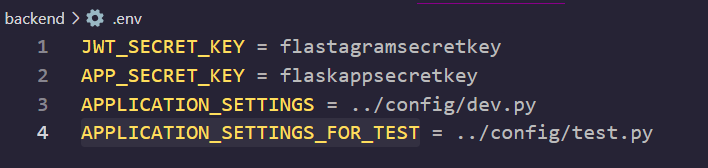
그리고, 테스트를 위한 config 파일을 따로 만들어 주겠습니다.

위와 같이 backend/config 아래에 test.py 를 작성해 주세요.
간단하게, 위에서 작성한 다섯 개의 메서드에 대해서 테스트를 수행해 보겠습니다. tests 라는 폴더를 만들고, 비어있는 __init__.py, test_post.py 를 작성해 주세요.
그리고, test_post.py 아래에 다음의 내용을 입력합니다.
import email
import os
import api
import unittest
import tempfile
from api.db import db
from dotenv import load_dotenv
from api.models.post import PostModel
from api.models.user import UserModel
from sqlalchemy.orm import Session
class CommonTestCaseSettings(unittest.TestCase):
"""
테스트를 위한 공통 셋업
"""
def setUp(self):
"""
테스트를 위한 사전 준비
backend/config/test.py 를 사용
.env 파일의 APPLICATION_SETTINGS_FOR_TEST 환경 변수 사용
app.test_client() 로 테스트를 위한 클라이언트 생성
테스트를 위한 임의의 유저 한 명 생성
"""
self.app = api.create_app()
self.ctx = self.app.app_context()
self.ctx.push()
load_dotenv(".env", verbose=True)
self.app.config.from_object("config.test")
self.app.config.from_envvar("APPLICATION_SETTINGS_FOR_TEST")
self.app.config.update(RESTFUL_JSON=dict(ensure_ascii=False))
self.client = self.app.test_client()
db.create_all()
UserModel(username="test_user", password="12345", email="test@example.com").save_to_db()
def tearDown(self):
"""
테스트가 끝나고 수행되는 메서드, 데이터베이스 초기화
"""
db.session.remove()
db.drop_all()이 곳에서는 게시물에 관한 것을 테스트할 텐데, 데이터베이스 설정을 몇 개의 클래스가 공유할 것이므로 위의 CommonTestCaseSettings 를 상속받아 사용하도록 하겠습니다.

바로 아래에 위의 클래스를 작성합니다. 테스트할 것을 잘 읽어보겠습니다. 인스타그램을 보면 최신 게시물 순으로 게시물이 나타나고, 한 번에 모든 게시물 데이터를 받아오지 않고 사용자가 스크롤을 내릴 때마다 새 게시물이 로드되죠? (한 번 요청을 보낼 때에 모든 게시물의 목록을 받아온다면, 그 부하는 엄청날 겁니다.) 그것을 위해서 “최신순 정렬, 페이지네이션” 을 테스트해 보도록 하겠습니다.
일단은 구현을 하지 않았으므로, 페이지네이션을 먼저 구현해 볼까요?
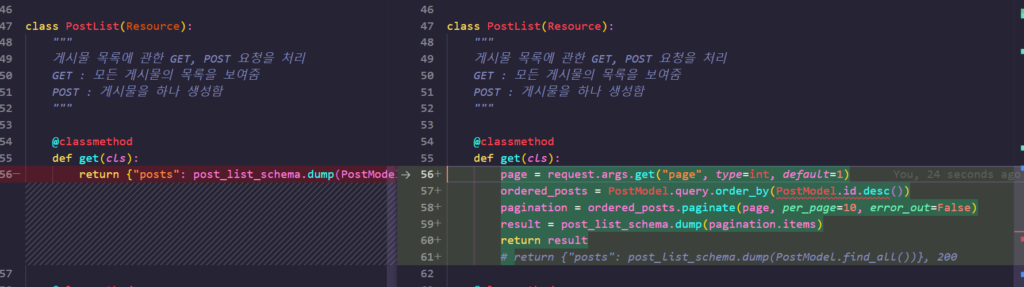
먼저 57번째 줄에서 primary key 의 역순으로 정렬을 시도하고, 58번째 줄에서 페이지네이션을 추가했습니다.
이후 그것들의 items 들만 직렬화하여 결과를 리턴해주도록 하였습니다. 이제 테스트 코드를 작성하고, 우리가 원하는 결과가 나오는지 확인해 보겠습니다!

get_post_list 의 시작은 임의의 게시물 백 개를 만들면서 시작합니다. 페이지네이션이 적용되어 있다면, posts/ 에 접속했을 때에 페이지의 기본값인 1이 적용될 것이고, 1페이지의 첫 번째 게시물의 id는 100, 마지막 id는 91이 되어야 합니다. 두 번째 경우에도 마찬가지로 90, 81이 나와야 하겠죠?
import email
import os
from urllib import response
import api
import unittest
import tempfile
from api.db import db
from dotenv import load_dotenv
from api.models.post import PostModel
from api.models.user import UserModel
from sqlalchemy.orm import Session
class CommonTestCaseSettings(unittest.TestCase):
"""
테스트를 위한 공통 셋업
"""
def setUp(self):
"""
테스트를 위한 사전 준비
backend/config/test.py 를 사용
.env 파일의 APPLICATION_SETTINGS_FOR_TEST 환경 변수 사용
app.test_client() 로 테스트를 위한 클라이언트 생성
테스트를 위한 임의의 유저 한 명 생성
"""
self.app = api.create_app()
self.ctx = self.app.app_context()
self.ctx.push()
load_dotenv(".env", verbose=True)
self.app.config.from_object("config.test")
self.app.config.from_envvar("APPLICATION_SETTINGS_FOR_TEST")
self.app.config.update(RESTFUL_JSON=dict(ensure_ascii=False))
self.client = self.app.test_client()
db.create_all()
UserModel(username="test_user", password="12345", email="test@example.com").save_to_db()
def tearDown(self):
"""
테스트가 끝나고 수행되는 메서드, 데이터베이스 초기화
"""
db.session.remove()
db.drop_all()
class PostListTestCase(CommonTestCaseSettings):
"""
/posts 에 대한 GET, POST 요청을 테스트한다.
GET /posts -> 모든 게시물의 목록을 반환
POST /posts -> 새로운 게시물을 하나 생성
"""
def test_get_post_list(self):
"""
1. 임의의 게시물 100개를 생성하고, /posts 에 요청을 보냄
2. 임의의 게시물의 형태는 (제목:1번째 테스트 게시물입니다. / 내용:1번째 테스트 게시물의 내용입니다) 와 같은 형태가 될 것임
3. /posts 에 요청을 보내면, 게시물의 목록이 나타나야 함
4. 게시물의 목록은 10개씩, 역 pk 순으로 페이지네이션 처리되어야 함
5. 고로, 첫 번째 게시물의 id 는 100이어야 함
6. 첫 번째 페이지의 마지막 게시물의 id는 91이어야 함
"""
# 임의의 게시물 100개 생성
dummy_posts = []
for i in range(100):
dummy_posts.append(
PostModel(
title=f"{i+1}번째 테스트 게시물입니다.", content=f"{i+1}번째 테스트 게시물의 내용입니다.", author_id=1
)
)
db.session.bulk_save_objects(dummy_posts)
db.session.commit()
# 게시물의 첫 번째 페이지로 요청을 보낸다.
response = self.client.get("http://127.0.0.1:5000/posts/").get_json()
# 게시물 목록의 맨 첫 번째 게시물의 id 는 100이어야 한다.
self.assertEqual(100, response[0]["id"])
# 게시물 목록의 맨 마지막 게시물의 id 는 91 이어야 한다.
self.assertEqual(91, response[-1]["id"])
# 게시물의 두 번째 페이지로 요청을 보낸다.
response = self.client.get("http://127.0.0.1:5000/posts/?page=2").get_json()
# 게시물 목록의 두 번째 페이지의 맨 첫 번째 게시물의 id 는 90이어야 한다.
self.assertEqual(90, response[0]["id"])
# 게시물 목록의 맨 마지막 게시물의 id 는 81 이어야 한다.
self.assertEqual(81, response[-1]["id"])
if __name__ == "__main__":
unittest.main()
위의 코드를 모두 작성하고 테스트를 수행해 보세요. OK가 나올 겁니다.
다음에는, 게시물 목록에 대한 post/ 상세에 대한 get/put/delete 메서드를 테스트해 본 다음, JWT를 이용한 로그인을 구현해 보겠습니다!
