[Flask] – “인스타그램 클론코딩 – Instagram Clone (6)”
[Flask] – “인스타그램 클론코딩 – Instagram Clone (6)”
이번에 수행할 것
- 무한 스크롤 : 실제 인스타그램을 사용해 보신 분들은 아시겠지만, 스크롤을 내릴 때마다 새로운 게시물이 로드됩니다. 그것을 위해서 우리는 백엔드 단에서 페이지네이션을 구현해 두었죠. 실제 자바스크립트 코드로 무한 스크롤을 구현하며 어떻게 프론트엔드 단에서 페이지네이션을 확인하는지를 알아봅니다.
- 댓글 API : 생각해 보면 게시물과 댓글의 CRUD 를 처리하는 것은 게시물 API의 그것과 많은 부분을 공유합니다. 다만, 현재 서비스에서는 댓글 상세 조회 기능 정도는 필요가 없을 것 같아요. 이번 시간에는 댓글 목록 조회, 새로운 댓글 작성, 특정 댓글 수정, 특정 댓글 삭제를 구현합니다.
폴더 구조 리팩토링
우리가 작성한 express 는 html, css, js 같은 정적 파일들을 서빙하는 역할만 했는데, assets/ 와 html 파일들을 굳이 분리해 두는 것은 합리적이지 않아 보여요. 몇 가지 폴더 구조를 바꿔 보겠습니다.
server/ 안에 있던 파일들을 모두 frontend/ 아래에 옮겨 주고, server 디렉토리는 삭제합니다.
assets/ 아래에 html 폴더를 만들어준 다음,
만들어두었던 2개의 html 파일을 그곳으로 이동합니다.
최종 구조는 아래와 같겠네요. :)
이제 서빙할 정적 파일들의 위치가 바뀌었으므로 아래와 같이 파일들의 경로를 바꾸어 줍니다.
(6, 14 18번 줄)
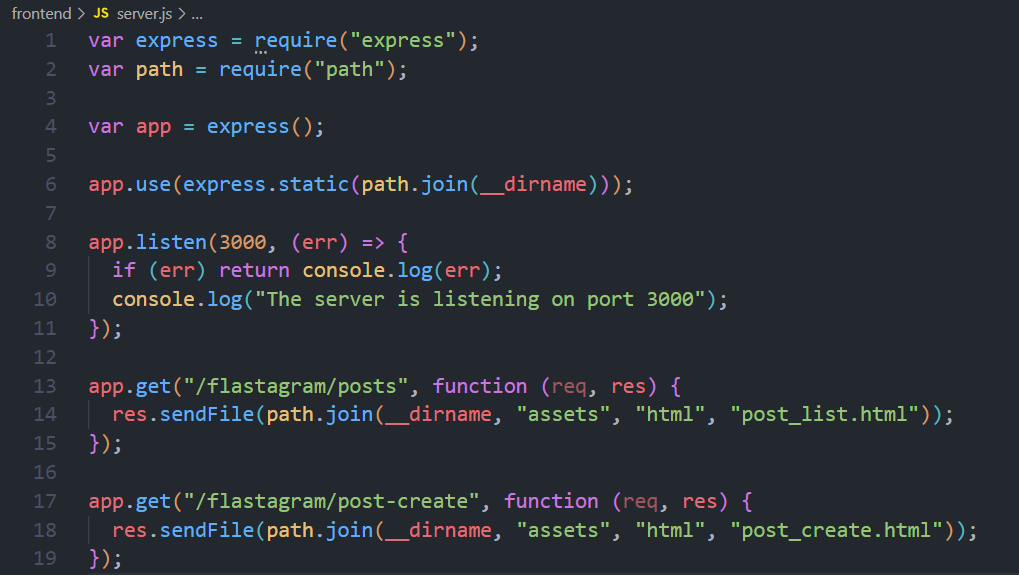
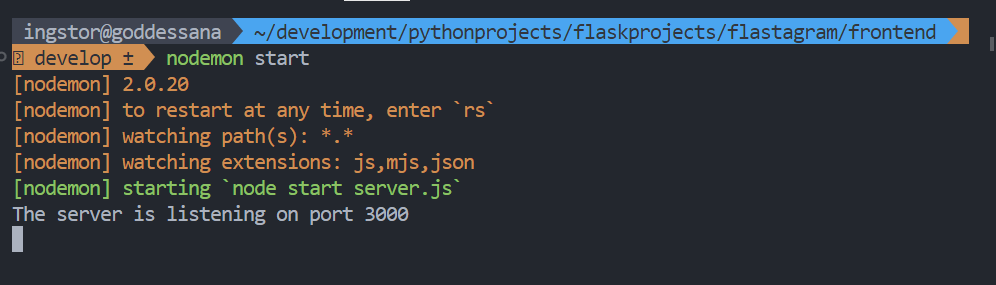
위와 같이 서버를 열어 주시고,
파일들이 잘 로드되는 것을 확인해 주세요. :)
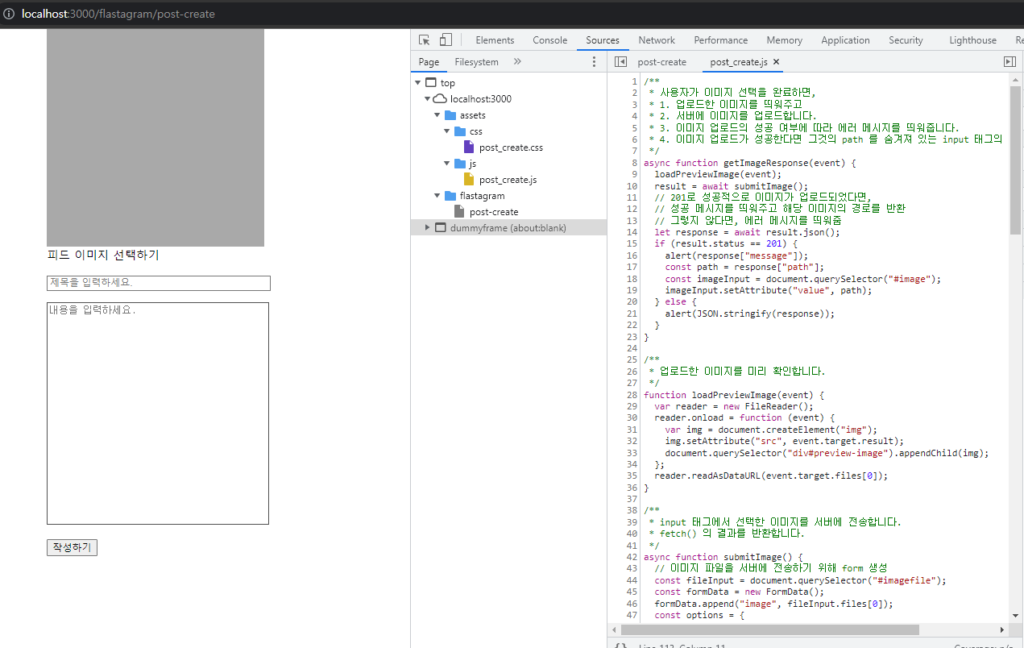
/flastagram/post-create 로 접속해도 파일들이 404 에러 없이 잘 로드되는 것을 확인할 수 있네요!
무한 스크롤 구현하기
우리가 사용하는 인스타그램에서는 스크롤을 내리면 계속 새로운 포스트가 나옵니다. 이번에는 이것을 구현해 보겠습니다. 그것을 위해서 백엔드 단에서는 페이지네이션 처리를 했었죠. 긴 여정의 시작..입니다.
** 주의사항 : 최대한 깔끔한 자바스크립트 코드를 작성하려고 노력했으나 스스로 작성하면서도 레거시한 코드라는 것이 느껴지네요. “백엔드 단에서 구현한 페이지네이션을 이러한 식으로 활용할 수 있다” 정도의 과정으로 이해하시고, 꼭 해당 코드의 리팩토링을, 그리고 그것을 수행하는 과정을 기록하며 공부해 보시는 것을 적극 추천드립니다! **
간단한 논리는, 스크롤을 어느 정도 내리면 -> 다음 게시물들이 로드되도록 하면 됩니다. 당연히, 로딩되는 페이지는 우리의 플라스크 서버가 페이지네이션 처리한 것을 이용할 겁니다.
그러므로, 우리는 getPostListDatafromAPI() 메서드를 “원하는 페이지를 가져올 수 있도록” 고쳐보겠습니다.
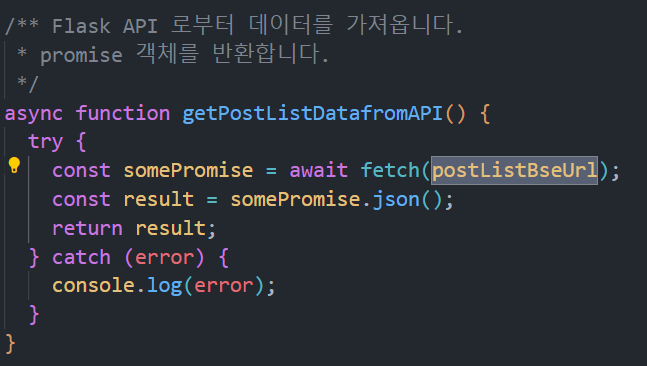
시작은 저 postListBseUrl 입니다. 해당 값은 우리의 게시물 목록 API의 URL 을 가리키고 있습니다.

이 부분에서 2페이지를 보여주고 싶다면, postListBseUrl 은 아래와 같아야 합니다.
"http://127.0.0.1:5000/posts/?page=2"이 부분에서 차이를 찾을 수 있습니다. (기본 URL)?page=(원하는 페이지) 가 되겠네요.
/** Flask API 로부터 데이터를 가져옵니다.
* promise 객체를 반환합니다.
*/
async function getPostListDatafromAPI(page = 1) {
try {
const somePromise = await fetch(postListBseUrl + "?page=" + page);
const result = somePromise.json();
return result;
} catch (error) {
console.log(error);
}
}그러면 해당 함수를 위와 같이 고칠 수 있겠네요. page 를 받아서, 원하는 페이지를 조회할 수 있도록 하였습니다.
/**
* getPostListDatafromAPI() 로부터 게시물 목록 데이터를 불러옵니다.
* 불러온 데이터 결과의 길이만큼 (페이지네이션 처리) 게시물을 반복해 그립니다.
*/
function loadPosts(page = 1) {
getPostListDatafromAPI((page = page))
.then((result) => {
for (let i = 0; i < result.length; i++) {
copyDiv();
// 커버 이미지 요소를 선택하고 그립니다.
const coverImageElements = document.querySelector(".post-image");
coverImageElements.src =
imageRetrieveBseUrl + result[result.length - 1 - i]["image"];
// 저자 이름 요소를 선택하고, 그립니다.
const upAuthorElement = document.querySelector(".author-up");
upAuthorElement.innerText =
result[result.length - 1 - i]["author_name"];
const downAuthorElement = document.querySelector(".author-down");
downAuthorElement.innerText =
result[result.length - 1 - i]["author_name"];
// 제목 요소를 선택하고 그립니다.
const titleElement = document.querySelector(".title");
titleElement.innerText = result[result.length - 1 - i]["title"];
// 내용 요소를 선택하고 그립니다.
const contentElement = document.querySelector(".content");
contentElement.innerText = result[result.length - 1 - i]["content"];
// 게시물이 없다면 none 처리를 합니다.
if (i == 0) {
document.getElementById("copied-post").style.display = "none";
}
}
})
.catch((error) => {
console.log(error);
});
}loadPosts() 함수도 위와 같이 고쳐주도록 합시다.
마지막으로, 우리는 새로운 게시물을 아래에 계속 그려나갈 것이므로 하나의 게시물을 덮어주는 div 하나를 정의해 주겠습니다.
무한 스크롤을 위한 삽질
모든 게 마음먹기 달렸어
거북이 – 빙고
어떤 게 행복한 삶인가요 (아싸!)
사는 게 힘이 들다 하지만
쉽게만 살아가면 재미없어 bingo! (bingo!)
뼛속까지 백엔드인 – 아니 자바스크립트와 어색한 사이인 저로서는 이거 하나 구현하는 데에도 엄청난 시간을 쏟았던 것 같습니다. 삽질의 효율은 좋지 않았지만 어쩌겠어요. 저도 사실 다른 자료들 보고 금방 할 줄 알았습니다. 하지만, 거북이의 노래 “빙고” 의 가사가 말해주듯 쉽게만 살아가면 정말 재미없습니다. 전 정말 재미없게 살고 싶은데 말이에요. 아무튼,, 시작입니다.
무한 스크롤의 생각의 흐름은 아래와 같습니다. 천천히 따라와 봅시다.
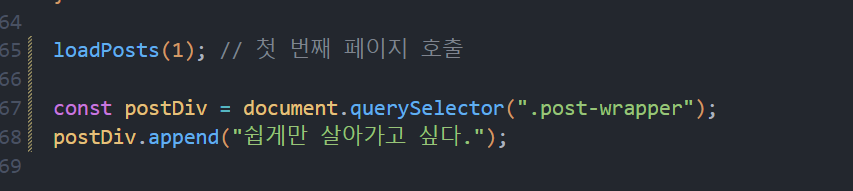
먼저 생각나는 것은 post-wrapper div 안에 append 를 수행함으로서 새로운 게시물을 그려야 한다는 것입니다. 위처럼 코드를 작성하면, postDiv 라는 엘리먼트 아래에 “쉽게만 살아가고 싶다” 라는 문자열이 붙을 겁니다. 자식 노드로서요.

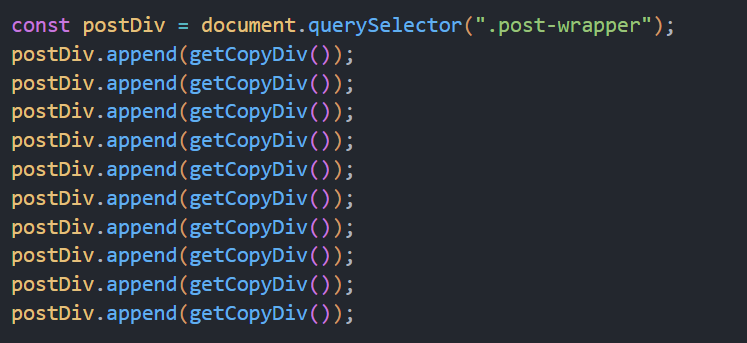
그러면, 원래의 빈 게시물을 하나 복사해서 아래에 직접 붙여 넣으면 되겠네요. 그것을 위해 함수 하나 정도 정의해 주죠. 아래와 같겠습니다.

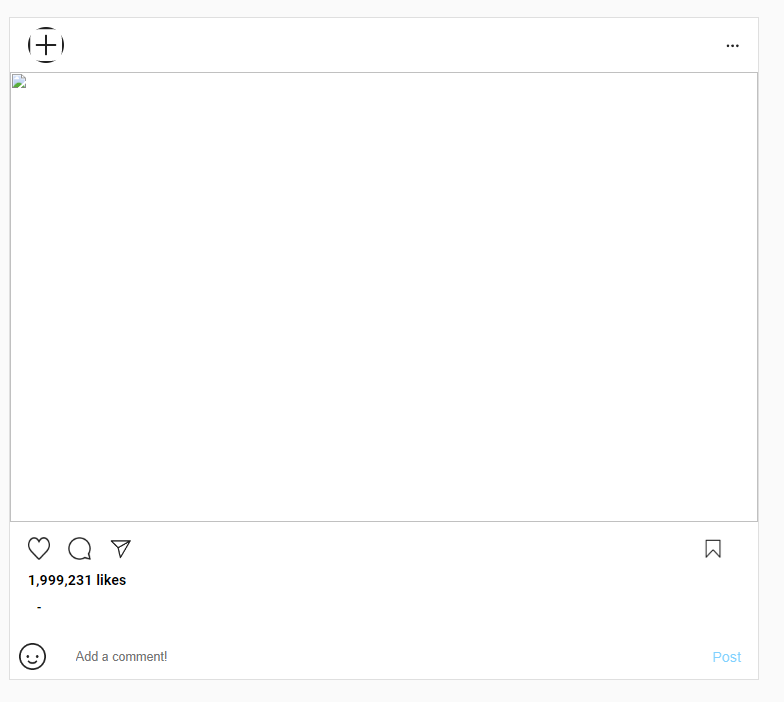
good! 성공적으로 기본 게시물 div 하나를 복사해서 아래에 붙였습니다.
2페이지 전체를 불러온다면, 게시물은 10개가 더 로딩되어야 합니다. 그러면 아래와 같이 10번 반복하고 10개를 채워주면 되려나요? 첫째로 게시물 데이터 불러오는 것은 괜찮습니다. 다행히 우리는 미리 정의해 둔 getPostListDatafromAPI() 함수가 있습니다. 이 함수를 호출한다는 것은 우리의 플라스크 서버로부터 게시물 목록 API 정보들을 불러온다는 것을 의미했었죠?
좋아요. 위 부분은 반복문으로 퉁칠 수 있다고 합시다. “API 로부터 게시물 데이터를 받아와서, 적당하게 뿌려준 다음, 완성된 div를 반복해서 append 해 준다” 를 구현해야 합니다. 그걸 또 쪼개면, (API 로부터 데이터를 받아와서) 는 이미 완성, (적당하게 뿌려준 다음) 은 미완성이네요. 이를 구현합시다.
대충 함수 하나 아래와 같이 구성해 보겠습니다.
/**
* 제목, 내용, 저자, 사진을 받아 해당 div를 하나의 게시물로 완성합니다.
*/
function getCompletedPost(
titleValue,
contentValue,
authorNameValue,
feedImgValue
) {
div = getCopyDiv();
let authorUpImg = div.children[0].children[0].children[0];
let authorUpName = div.children[0].children[0].children[1];
let feedImg = div.children[1];
let authorDownName = div.children[2].children[3];
let title = div.children[2].children[4];
let content = div.children[2].children[5];
let postTime = div.children[2].children[6];
title.innerText = titleValue;
content.innerText = contentValue;
authorUpName.innerText = authorNameValue;
authorDownName.innerText = authorNameValue;
feedImg.src = feedImgValue;
return div;
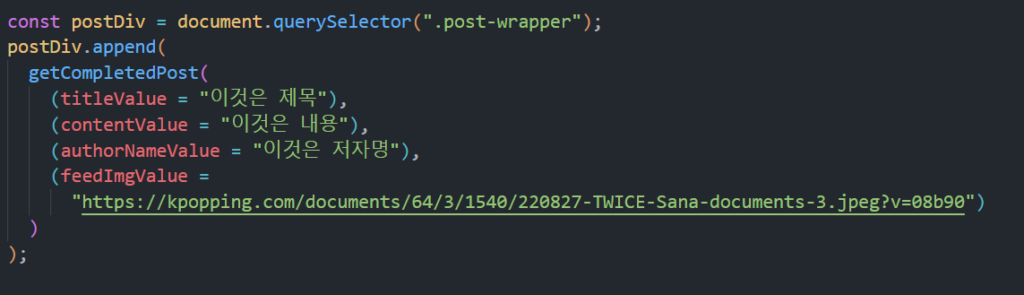
}그리고 이를, 임의의 값을 넣어서 직접 호출해 봅시다. 값은 아래와 같이 들어갈 거에요.
결과는,
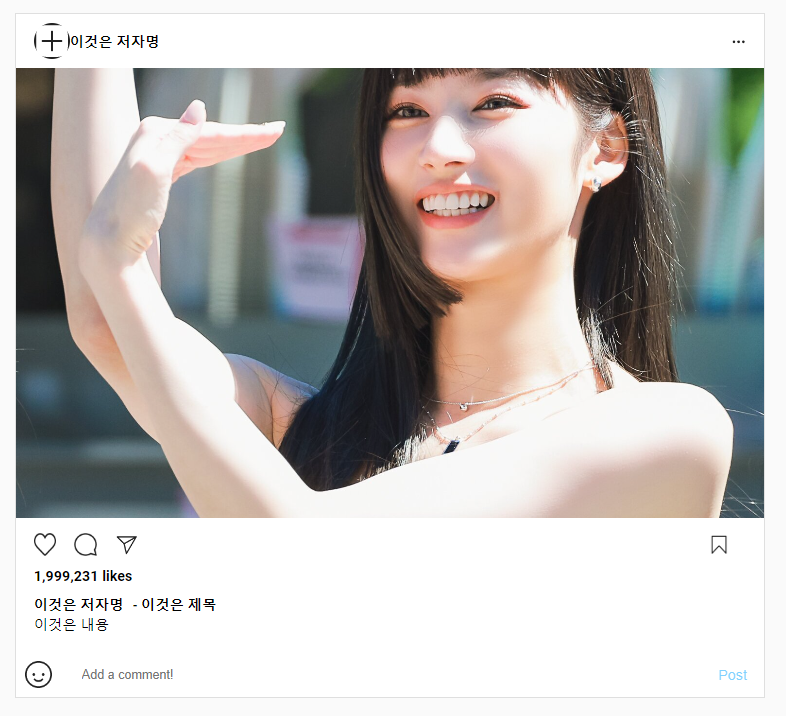
좋아요, 아직까진 우리가 원하는 대로 사진과 제목명 등 잘 적용되었네요.
- (API 로부터 데이터를 받아와서) 는 이미 완성
- (적당하게 뿌려준 다음) 은 완성 직전입니다. 뿌려주는 것까진 되었어요.
이제 “데이터만 있으면, 새롭게 게시물 아랫쪽에 붙이는 것” 까진 되었습니다. “데이터를 받아오는 것” 은 이미 이전에 작성했던 함수가 있었으니 괜찮습니다.
그러면, 이제 데이터를 받아와서 반복해서 그려주는 메서드 하나 작성해 봅시다.
/**
* 게시물 데이터를 받아온 다음,
* 일정한 조건이 되면 호출되는 메서드입니다.
* 페이지를 받아서, 적절한 데이터를 받아 화면에 그립니다.
*/
function loadMorePosts(page) {
getPostListDatafromAPI(page).then((result) => {
const postDiv = document.querySelector(".post-wrapper");
for (let i = 0; i < result.length; i++) {
const title = result[i]["title"];
console.log(i);
const content = result[i]["content"];
const author = result[i]["author_name"];
const image = imageRetrieveBseUrl + result[i]["image"];
postDiv.append(
getCompletedPost(
(titleValue = title),
(contentValue = content),
(authorNameValue = author),
(feedImgValue = image)
)
);
}
});
}
좋아요, 이 메서드는 무한 스크롤의 특정한 조건 (스크롤이 바닥에 닿는다거나 등) 이 되었을 때에 호출될 겁니다. 이것의 역할은 특정한 페이지를 받아서, 아래에 계속 새로운 게시물을 그려주는 역할을 합니다.
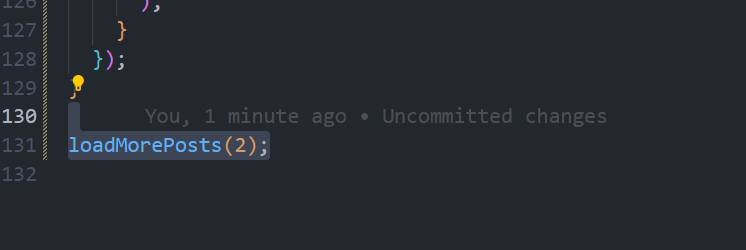
칼을 만들었다면 써 봐야죠.
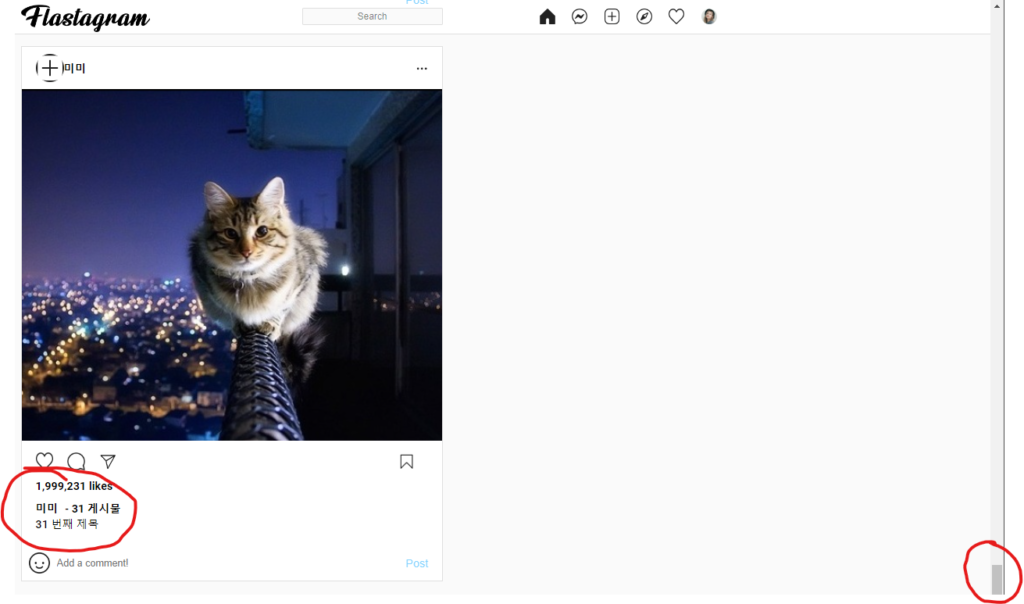
성공적으로, 다음 페이지의 게시물이 로드되네요. 스크롤이 맨 아래로 내려갔을 때에, 31번째 게시물이 성공적으로 로딩됩니다.
이제 해야 할 것은, 브라우저에서 현재 스크롤을 감지한 다음 스크롤이 일정 조건에 내려온다면 우리가 만들어 둔 loadMorePosts(page) 를 호출하는 것입니다.
우리의 자바스크립트 코드 전체가 조금 커졌으므로 메인 함수를 작성해서 그것으로 필요한 모든 함수를 호출하게끔 해 보겠습니다. 맨 아래에 해당 함수를 작성합니다. 그리고 메인 함수 내에서만 우리가 작성한 함수를 호출할 것이므로, function 혹은 async ~으로 시작하는 코드를 제외하고 호출하는 코드는 모두 삭제해 주세요. 현재 진행된 자바스크립트 코드 전체는 아래와 같습니다. (post_list.js)
// API 기본 URL들을 정의합니다.
const postListBseUrl = "http://127.0.0.1:5000/posts/";
const imageRetrieveBseUrl = "http://127.0.0.1:5000/statics/";
/** Flask API 로부터 데이터를 가져옵니다.
* promise 객체를 반환합니다.
*/
async function getPostListDatafromAPI(page = 1) {
try {
const somePromise = await fetch(postListBseUrl + "?page=" + page);
const result = somePromise.json();
return result;
} catch (error) {
console.log(error);
}
}
/**
* post Div 전체를 복사합니다.
*/
function copyDiv() {
const postDiv = document.querySelector(".post");
const newNode = postDiv.cloneNode(true);
newNode.id = "copied-post";
postDiv.after(newNode);
}
/**
* getPostListDatafromAPI() 로부터 게시물 목록 데이터를 불러옵니다.
* 불러온 데이터 결과의 길이만큼 (페이지네이션 처리) 게시물을 반복해 그립니다.
*/
function loadPosts(page = 1) {
getPostListDatafromAPI((page = page))
.then((result) => {
for (let i = 0; i < result.length; i++) {
copyDiv();
// 커버 이미지 요소를 선택하고 그립니다.
const coverImageElements = document.querySelector(".post-image");
coverImageElements.src =
imageRetrieveBseUrl + result[result.length - 1 - i]["image"];
// 저자 이름 요소를 선택하고, 그립니다.
const upAuthorElement = document.querySelector(".author-up");
upAuthorElement.innerText =
result[result.length - 1 - i]["author_name"];
const downAuthorElement = document.querySelector(".author-down");
downAuthorElement.innerText =
result[result.length - 1 - i]["author_name"];
// 제목 요소를 선택하고 그립니다.
const titleElement = document.querySelector(".title");
titleElement.innerText = result[result.length - 1 - i]["title"];
// 내용 요소를 선택하고 그립니다.
const contentElement = document.querySelector(".content");
contentElement.innerText = result[result.length - 1 - i]["content"];
// 게시물이 없다면 none 처리를 합니다.
if (i == 0) {
document.getElementById("copied-post").style.display = "none";
}
}
})
.catch((error) => {
console.log(error);
});
}
/**
* post Div 전체를 복사해 반환합니다.
*/
function getCopyDiv() {
const postDiv = document.querySelector(".post");
const newNode = postDiv.cloneNode(true);
newNode.id = "copied-post";
return newNode;
}
/**
* 제목, 내용, 저자, 사진을 받아 해당 div를 하나의 게시물로 완성합니다.
*/
function getCompletedPost(
titleValue,
contentValue,
authorNameValue,
feedImgValue
) {
div = getCopyDiv();
let authorUpImg = div.children[0].children[0].children[0];
let authorUpName = div.children[0].children[0].children[1];
let feedImg = div.children[1];
let authorDownName = div.children[2].children[3];
let title = div.children[2].children[4];
let content = div.children[2].children[5];
let postTime = div.children[2].children[6];
title.innerText = titleValue;
content.innerText = contentValue;
authorUpName.innerText = authorNameValue;
authorDownName.innerText = authorNameValue;
feedImg.src = feedImgValue;
return div;
}
/**
* 게시물 데이터를 받아온 다음,
* 일정한 조건이 되면 호출되는 메서드입니다.
* 페이지를 받아서, 적절한 데이터를 받아 화면에 그립니다.
*/
function loadMorePosts(page) {
getPostListDatafromAPI(page).then((result) => {
const postDiv = document.querySelector(".post-wrapper");
for (let i = 0; i < result.length; i++) {
const title = result[i]["title"];
console.log(i);
const content = result[i]["content"];
const author = result[i]["author_name"];
const image = imageRetrieveBseUrl + result[i]["image"];
postDiv.append(
getCompletedPost(
(titleValue = title),
(contentValue = content),
(authorNameValue = author),
(feedImgValue = image)
)
);
}
});
}
function main() {}
맨 아래의 main() 함수가 어떻게 돌아가야 할 지 한번 생각해 봅시다. 첫째로는, 1페이지 게시물들을 모두 가져와야 합니다.
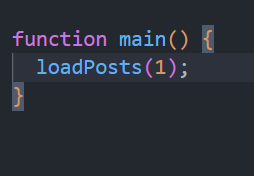
그리고, 메인 함수의 로직은 아래와 같겠네요.

이를 위해서 이용해볼 것이 있습니다. 바로, IntersectionObserver 입니다.
IntersectionObserver
말보단 코드로 먼저 살펴봅시다. 먼저 post_list.html 에 아래의 코드를 추가합니다. 우리는 스크롤이 맨 아래에 다다르면 게시물이 로드되도록 한다고 했었죠. 맨 아래의, “bottom” 이라는 클래스를 속성으로 가지는 div 를 발견했다는 것은 스크롤이 맨 아래로 내려갔다는 걸 의미할 겁니다.
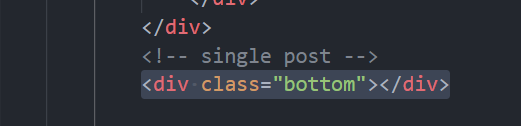
그리고 그냥 아래처럼 자바스크립트 코드를 작성해 줍니다. (지금, 우리는 코드의 맨 아랫부분만 만지고 있습니다.)
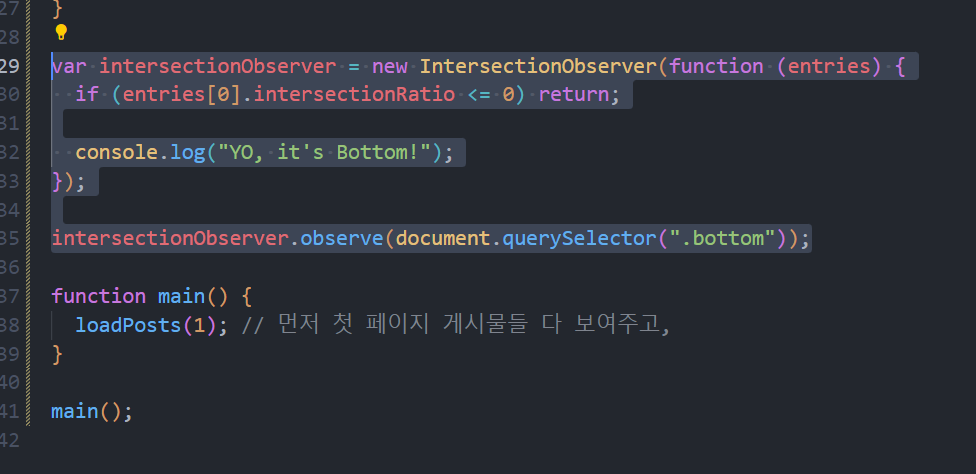
그리고 브라우저에 가서, 한번 스크롤을 아래로 쭉 내려봅시다.
우리가 완벽하게 원했던 그것이 구현되었네요.
이제 로직은 단순합니다. 페이지를 신경써서, 게시물이 로드되면 페이지의 숫자를 하나 늘려두면 되겠네요 !
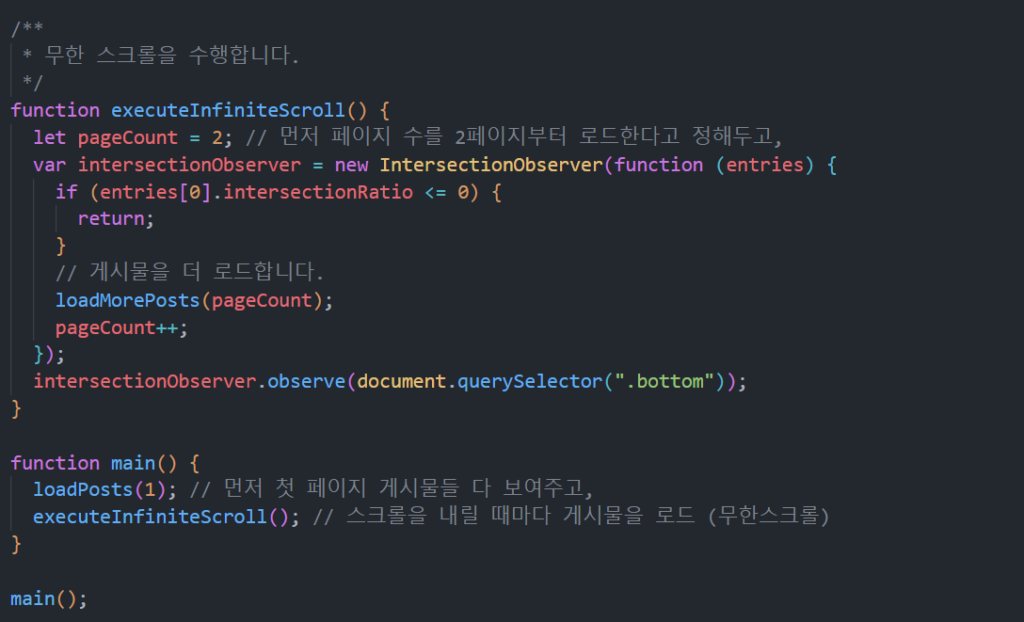
아래와 같이 무한 스크롤이 구현된 것을 확인할 수 있습니다., :D
댓글 API 구현하기
좋습니다. 여기까지 잘 구현하셨다면 이제 기능을 몇 가지 추가해 보겠습니다. 인스타그램에는 댓글 기능이 있죠. 블로그 개발 때에 알게 되었듯이, 게시물과 댓글은 일대다 관계입니다. 그리고 그것은 이미 우리의 모델에 정의되어 있습니다.
우리가 구현할 엔드포인트는 아래와 같습니다. 생각해 보면 한 댓글에 대한 상세조회는 굳이 구현할 필요 없을 것 같아요.
────────────────────────────────────────────────────────────────────────────
GET | posts/<id>/comments => 특정 게시물에 작성된 모든 댓글을 조회합니다.
POST | posts/<id>/comments => 특정 게시물에 댓글을 하나 추가합니다.
────────────────────────────────────────────────────────────────────────────
PUT | posts/<id>/comments/<id>/ => 특정 게시물의 특정 댓글을 수정합니다.
DELETE | posts/<id>/comments/<id>/ => 특정 게시물의 특정 댓글을 삭제합니다.
────────────────────────────────────────────────────────────────────────────댓글 API 에 대한 짧은 고찰
댓글 목록 조회에 대해 잠깐 생각해 봅시다. 댓글과 게시물의 관계는 아래와 같습니다.
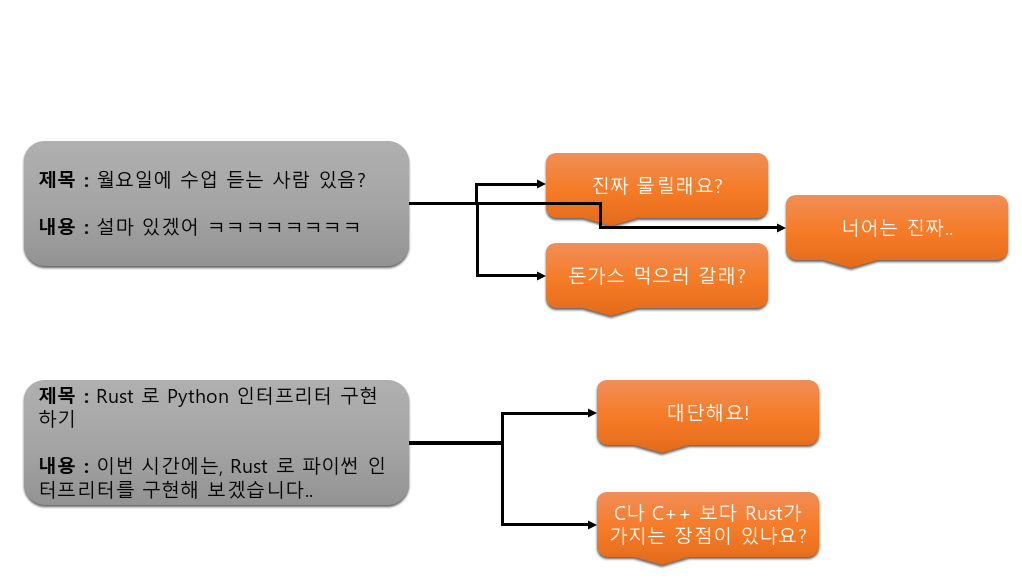
보통 “댓글 목록 조회를 한다” 는 것은 “한 게시글” 에 대한 모든 댓글을 조회한다는 것을 의미합니다. 예컨대, 서버에 “댓글 목록 조회를 할래~” 를 요청하면 서버는 다음과 같은 값을 보내주면 안 되겠죠. 서버는 “어떤 게시물의 모든 댓글 목록” 을 응답해 주어야 하지, “모든 댓글 목록” 을 응답해주면 안 됩니다.(안 된다는 것은 현재 우리가 구현하고자 하는 것과 맞지 않다는 것을 의미합니다.)

그렇게 하기 위해서, 우리는 엔드포인트를 posts/<id>/comments/ 처럼 계획을 해 두었습니다. 예컨대, 사용자가 GET posts/1/comments 를 요청한다면, “1번 게시물에 있는 모든 댓글을 볼래~” 를 의미합니다. 게시물을 특정한 것입니다.
이를 구현하기 위해서 resources/comment.py 를 새로 작성해 주겠습니다.
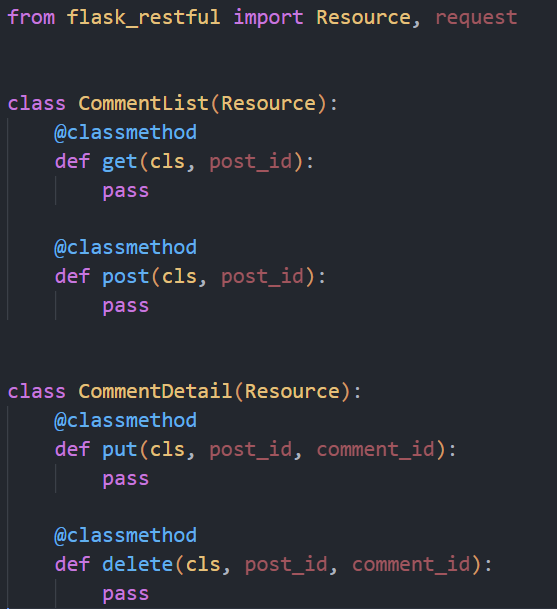
댓글 목록에 대한 GET / POST, 댓글 상세에 대한 PUT / DELETE 를 처리하는 리소스 두 개를 작성했습니다. (이제 import 는 알아서..!)
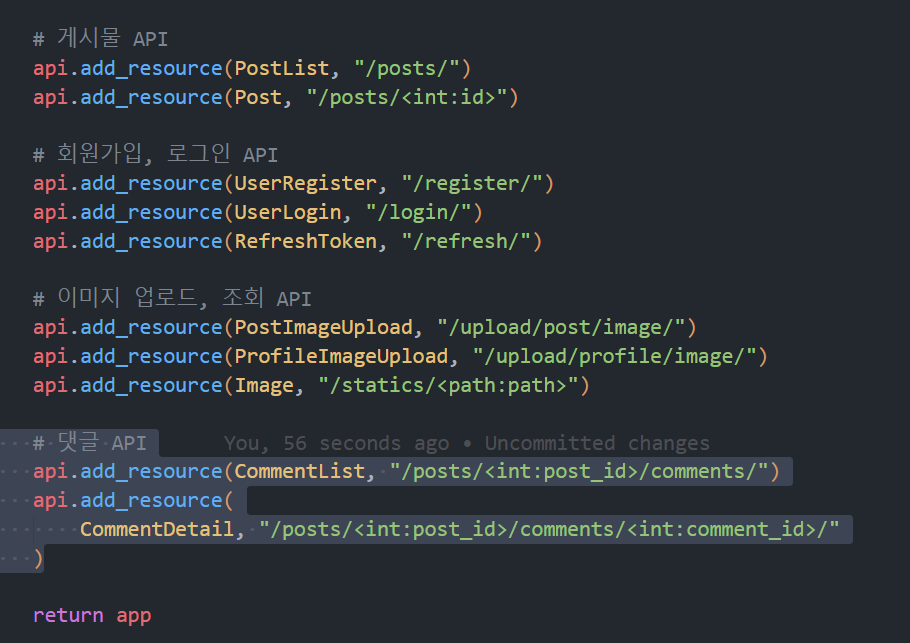
그리고, api/__init__.py 에 위처럼 우리가 만든 리소스를 등록해 줍시다.

api/resources/comment.py 의 CommentDetail 클래스에는 위의 두 개의 메서드가 작성됩니다. 주석 부분을 그대로 코드로 옮기면 되겠네요.
그러면 당연한 생각의 흐름으로, “댓글을 JSON 으로 바꾸어 표현해야 하니, 직렬화&역직렬화 규칙을 정의하는 Schema 를 작성해야겠네!” 가 됩니다.
from api.ma import ma
from api.models.comment import CommentModel
from marshmallow import fields
from api.ma import ma, Method
class CommentSchema(ma.SQLAlchemyAutoSchema):
"""
댓글 모델에 대한 직렬화 규칙을 정의합니다.
"""
created_at = fields.DateTime(format="%Y-%m-%d,%H:%M:%S")
updated_at = fields.DateTime(format="%Y-%m-%d,%H:%M:%S")
author_name = Method("get_author_name")
def get_author_name(self, obj):
return obj.author.username
class Meta:
model = CommentModel
dump_only = [
"author_name",
]
exclude = ("author_id", "post_id")
load_instance = True
include_fk = True
ordered = True
대부분의 코드는 게시물과 같습니다. 다만, 우리는 “어떤 게시물에 달린 댓글인가?” 중 “어떤 게시물의 id ” 는 url을 통해서 얻어올 것이므로 읽기 전용 필드로 두거나 제외해 줘도 되겠네요.
그러면, 리소스에서 GET 메서드를 받는 로직을 작성할 수 있을 줄..알았는데, 몇 가지 코드 수정을 더 해 주어야 합니다.

models/post/PostModel 클래스 안에서 위의 코드를 추가해 주세요. 이는 정렬을 수행하기 위함입니다.
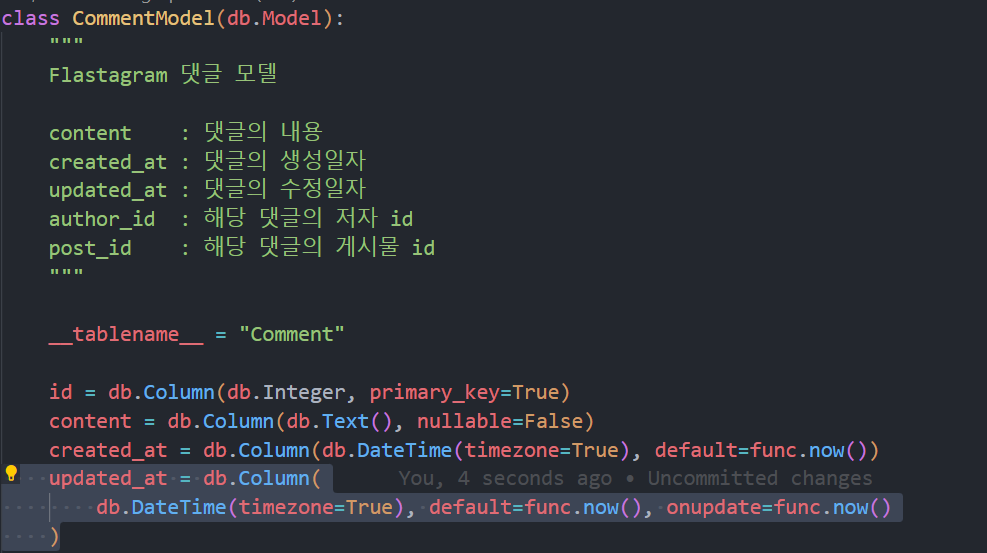
댓글의 수정일자도 자동으로 저장되도록 위와 같이 수정해 줍시다.
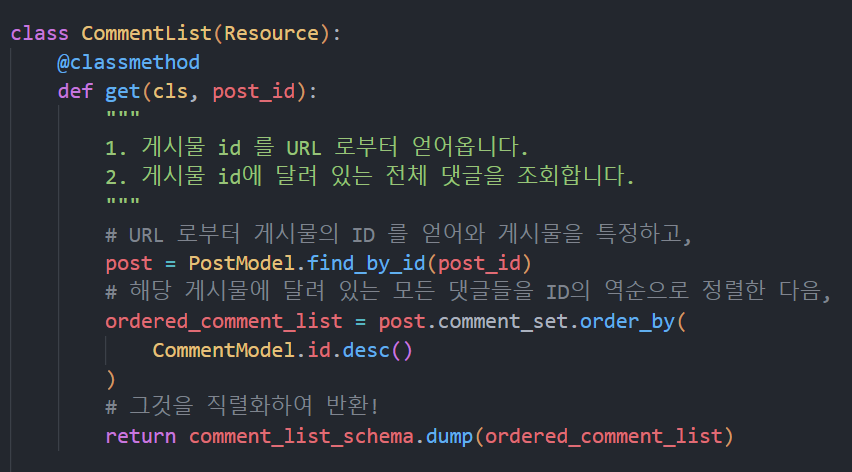
CommentList 의 GET 구현은 위와 같겠네요. URL로 게시물 id를 얻어와 해당 게시물에 있는 모든 댓글들을 id의 역순으로 정렬합니다.

댓글 몇 개를 작성해 볼까요? 우리는 50번째 게시물에 댓글을 작성했으므로, posts/50/comments/ 로 GET 요청을 날려 봅시다.
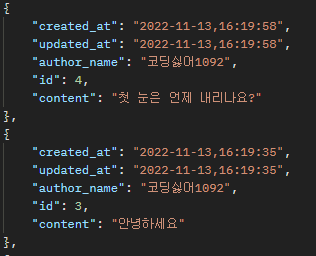
wow, 우리가 원하던 대로 댓글이 잘 작성되었고, 특정 게시물에 달려 있는 댓글들을 모두 응답해주는 것을 확인할 수 있네요.
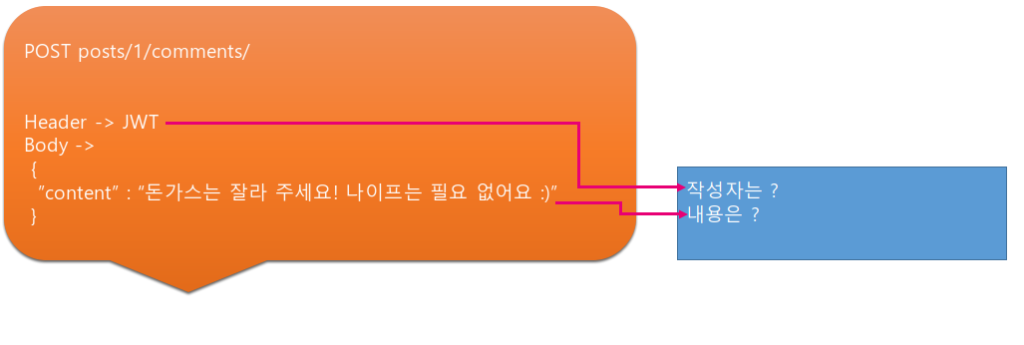
댓글 작성의 경우에는 어떨까요? 클라이언트는 백엔드 서버에게 아래와 같은 데이터를 보내줄 겁니다.
// header -> 인증 정보 (jwt)
{
"content":"댓글의 내용입니다."
}게시물과 마찬가지로 작성을 요청한 사람은 jwt를 보냄으로서 서버에게 “나 서울사는 미미요, 댓글좀 달겠소” 를 요청할 것이고, 서버는 그것을 이용해서 “미미가 댓글을 달았다” 를 처리하면 되겠네요. 그림으로 살펴보면 아래와 같겠습니다.
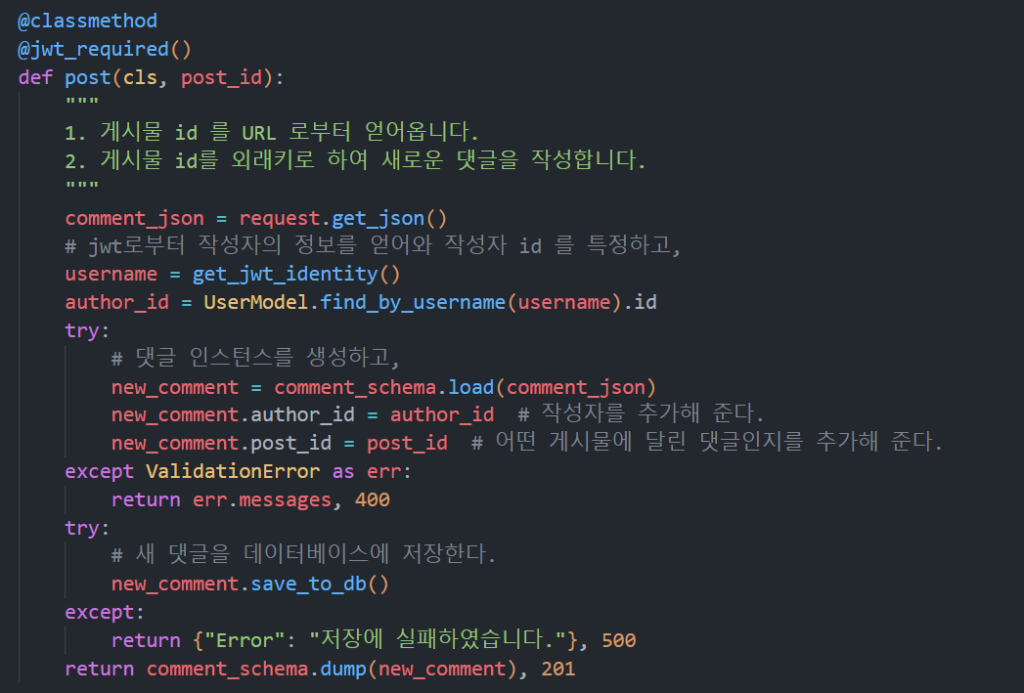
위와 같이 CommentResource 클래스 아래에 post 메서드를 정의해 줍니다.
이미 리소스는 등록된 상태이므로 POSTMAN 에서 요청을 날려 보죠!
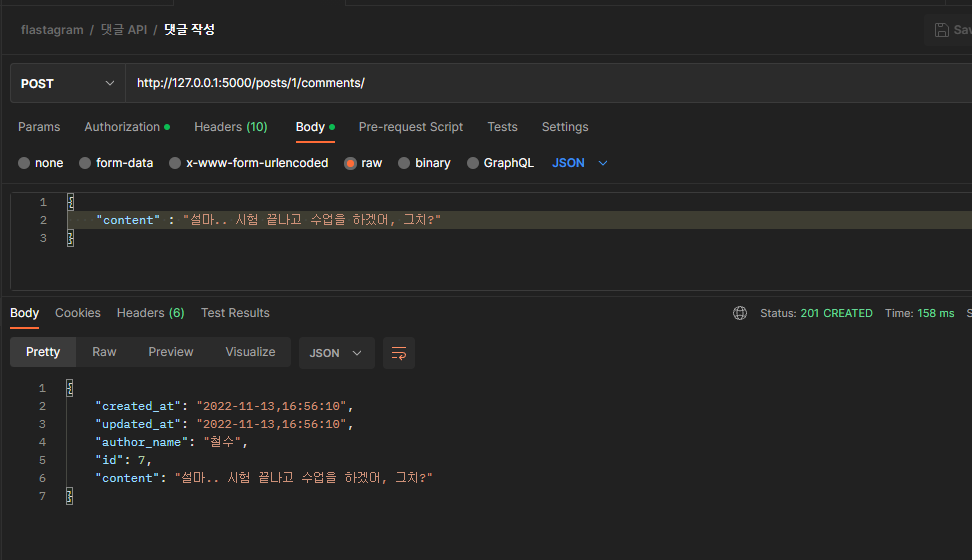
댓글이 성공적으로 생성된다면 서버는 201 상태 코드와 함께 작성된 댓글의 정보를 알려줄 겁니다.
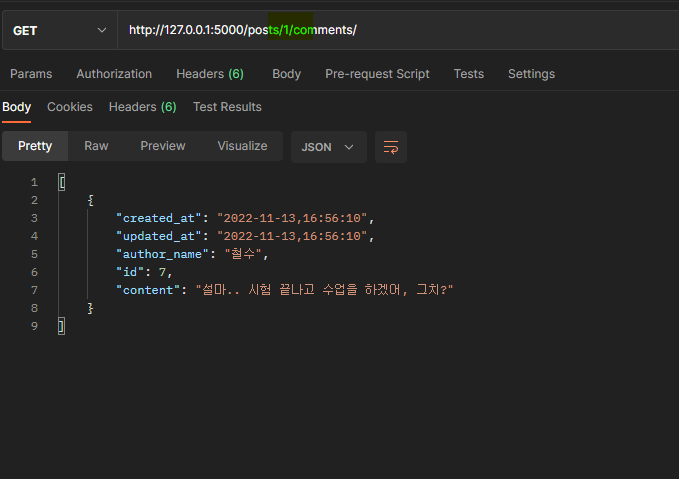
1번 게시물에 댓글을 작성했으므로, 댓글이 정상적으로 달렸는지 확인해 보면 정상적으로 달려있는 것을 확인할 수 있네요!
